Dario Amodei’s prepared remarks from the AI Safety Summit on Anthropic’s Responsible Scaling Policy

Before I get into Anthropic’s Responsible Scaling Policy (RSP), it’s worth explaining some of the unique challenges around measuring AI risks that led us to develop our RSP. The most important thing to understand about AI is how quickly it is moving. A few years ago, AI systems could barely string together a coherent sentence. Today they can pass medical exams, write poetry, and tell jokes. This rapid progress is ultimately driven by the amount of available computation, which is growing by 8x per year and is unlikely to slow down in the next few years. The general trend of rapid improvement is predictable, however, it is actually very difficult to predict when AI will acquire specific skills or knowledge. This unfortunately includes dangerous skills, such as the ability to construct biological weapons1. We are thus facing a number of potential AI-related threats which, although relatively limited given today’s systems, are likely to become very serious at some unknown point in the near future. This is very different from most other industries: imagine if each new model of car had some chance of spontaneously sprouting a new (and dangerous) power, like the ability to fire a rocket boost or accelerate to supersonic speeds.
We need both a way to frequently monitor these emerging risks, and a protocol for responding appropriately when they occur. Responsible scaling policies—initially suggested by the Alignment Research Center—attempt to meet this need. Anthropic published its RSP in September, and was the first major AI company to do so. It has two major components:
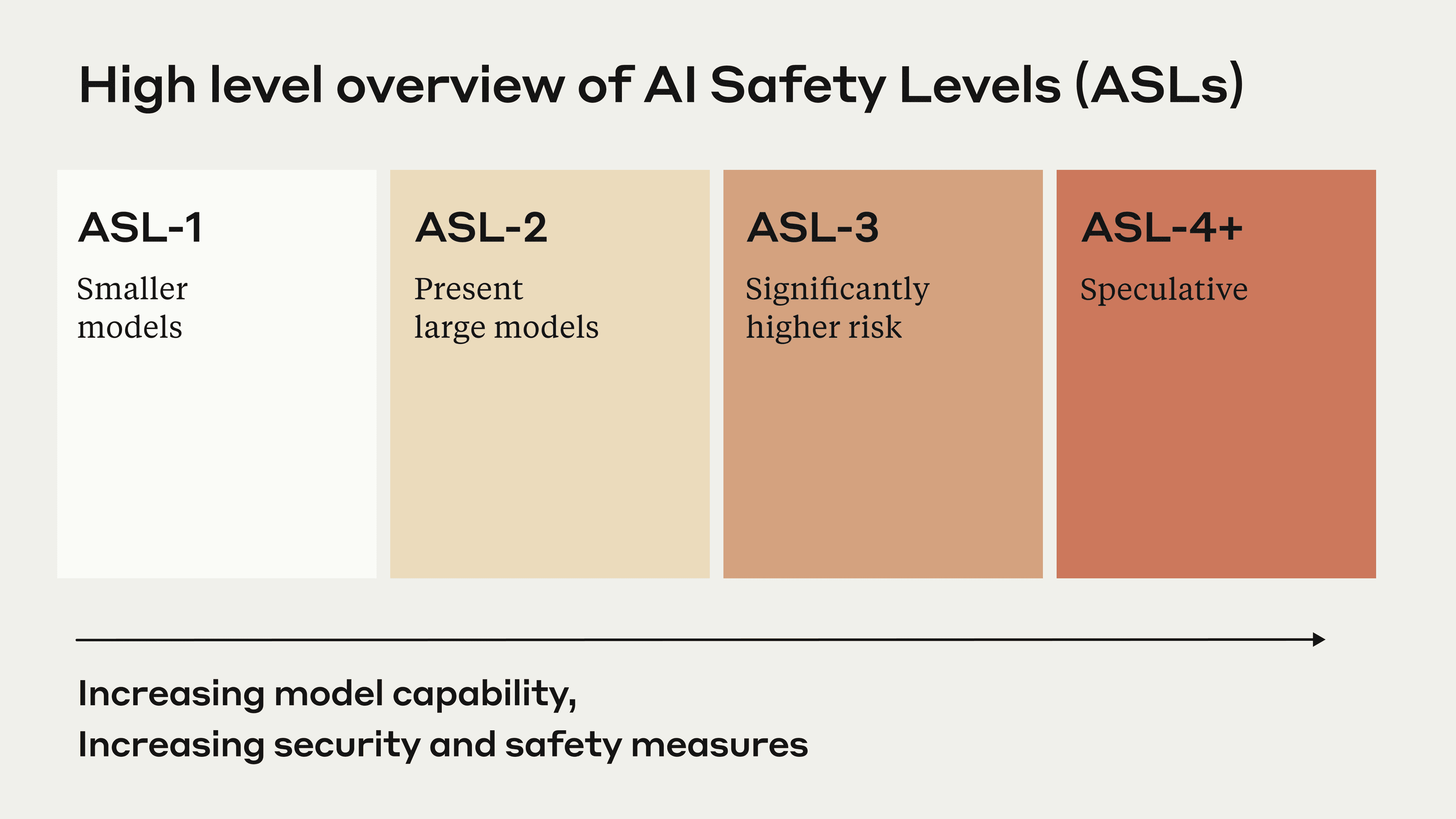
- First, we’ve come up with a system called AI safety levels (ASL), loosely modeled after the internationally recognized BSL system for handling biological materials. Each ASL level has an if-then structure: if an AI system exhibits certain dangerous capabilities, then we will not deploy it or train more powerful models, until certain safeguards are in place.
- Second, we test frequently for these dangerous capabilities at regular intervals along the compute scaling curve. This is to ensure that we don’t blindly create dangerous capabilities without even knowing we have done so.
In our system, ASL-1 represents models with little to no risk—for example a specialized AI that plays chess. ASL-2 represents where we are today: models that have a wide range of present-day risks, but do not yet exhibit truly dangerous capabilities that could lead to catastrophic outcomes if applied to fields like biology or chemistry. Our RSP requires us to implement present-day best practices for ASL-2 models, including model cards, external red-teaming, and strong security.
ASL-3 is the point at which AI models become operationally useful for catastrophic misuse in CBRN areas, as defined by experts in those fields and as compared to existing capabilities and proofs of concept. When this happens we require the following measures:
- Unusually strong security measures such that non-state actors cannot steal the weights, and state actors would need to expend significant effort to do so.
- Despite being (by definition) inherently capable of providing information that operationally increases CBRN risks, the deployed versions of our ASL-3 model must never produce such information, even when red-teamed by world experts in this area working together with AI engineers. This will require research breakthroughs, but we believe it is a necessary condition of safety.
- ASL-4 must be rigorously defined by the time ASL-3 is reached.
ASL-4 represents an escalation of the catastrophic misuse risks from ASL-3, and also adds a new risk: concerns about autonomous AI systems that escape human control and pose a significant threat to society. Roughly, ASL-4 will be triggered when either AI systems become capable of autonomy at a near-human level, or become the main source in the world of at least one serious global security threat, such as bioweapons. It is likely that at ASL-4 we will require a detailed and precise understanding of what is going on inside the model, in order to make an “affirmative case” that the model is safe.
Next, I’ll briefly mention some of our key practices and lessons learned, which we hope are helpful to others in crafting an RSP. First, deep executive involvement is critical. As CEO, I personally spent 10-20% of my time on the RSP for 3 months—I wrote multiple drafts from scratch, in addition to devising and proposing the ASL system. One of my co-founders devoted 50% of their time to developing the RSP for 3 months. Together, this sent a meaningful signal to employees that Anthropic’s leadership team takes the matter of AI safety seriously and is firmly committed to responsible scaling at the frontier.
Second, make the protocols outlined in the RSP into product and research requirements, such that they become baked into company planning and drive team roadmaps and expansion plans. Set the expectation that missing RSP deadlines directly impacts the company’s ability to continue training models and ship products on time. At Anthropic, teams such as security, trust and safety, red teaming, and interpretability, have had to greatly ramp up hiring to have a reasonable chance of achieving ASL-3 safety measures by the time we have ASL-3 models.
Third, accountability is necessary. Anthropic’s RSP is a formal directive of its board, which ultimately is accountable to our Long Term Benefit Trust, an external panel of experts with no financial stake in Anthropic. On the operational side, we will put in place a whistleblower policy before we reach ASL-3 and already have an officer responsible for ensuring compliance with the RSP and reporting to our Long Term Benefit Trust. As risk increases, we expect that stronger forms of accountability will be necessary.
Finally, I’d like to discuss the relationship between RSPs and regulation. RSPs are not intended as a substitute for regulation, but rather a prototype for it. I don’t mean that we want Anthropic’s RSP to be literally written into laws—our RSP is just a first attempt at addressing a difficult problem, and is almost certainly imperfect in a bunch of ways. Importantly, as we begin to execute this first iteration, we expect to learn a vast amount about how to sensibly operationalize such commitments. Our hope is that the general idea of RSPs will be refined and improved across companies, and that in parallel with that, governments from around the world—such as those in this room—can take the best elements of each and turn them into well-crafted testing and auditing regimes with accountability and oversight. We’d like to encourage a “race to the top'' in RSP-style frameworks, where both companies and countries build off each others’ ideas, ultimately creating a path for the world to wisely manage the risks of AI without unduly disrupting the benefits.
Footnotes
1. https://www.anthropic.com/inde...
Related content
PwC is deploying Claude to build technology, execute deals, and reinvent enterprise functions for clients
PwC will roll out Claude Code and Cowork starting with U.S. teams and expanding toward a global workforce of hundreds of thousands of professionals, establish a joint Center of Excellence, and train and certify 30,000 PwC professionals on Claude.
Read moreAnthropic forms $200 million partnership with the Gates Foundation
Read moreIntroducing Claude for Small Business
We're launching Claude for Small Business, a package of connectors and ready-to-run workflows that put Claude inside the tools small businesses use every day.
Read more