Subscribe to the Frontier Red Team newsletter
Get updates on our latest red-teaming research and findings.
Muhammad Maaz1,2, Liam DeVoe3, Zac Hatfield-Dodds2, Nicholas Carlini2
1MATS, 2Anthropic, 3Northeastern University
We developed an agent that can efficiently identify bugs in large software projects. To do this, our agent infers general properties of code that should be true, and then by applying property-based testing—a technique similar to fuzz testing—we are able to discover bugs in top Python packages like NumPy, SciPy, and Pandas. After extensive manual validation, we are in the process of reporting these bugs to the developers, several of which have already been patched.
For more information, read the full paper, take a look at the GitHub repository, or browse the bugs we found at our site.
Ensuring that programs are bug-free is one of the most challenging aspects of software engineering. Bugs frequently continue to lurk despite the developer’s best effort. The most common approach to testing code is with example-based tests: the developer writes out a specific example use-case, and then verifies that the actual output matches the expected output. For example, a developer might verify that a sort function called on the list [2, 10, 5, 4] would return the output [2, 4, 5, 10]. However, exhaustively covering a program with tests like this is challenging: bugs frequently remain in an edge case the developer did not test. After all, if a developer does not think to test an edge case, it is also likely the developer did not consider that case in the implementation!
In contrast, property-based testing is a software testing paradigm that aims to test whether a general property of the code holds for all (or most) inputs. A developer specifies a property or invariant about the program—for example, that JSON deserialization is the inverse of serialization—as well as a description of the kinds of inputs the property accepts (e.g., any JSON serializable objects). The property-based testing framework then automatically searches for a counterexample of this property by generating valid inputs as test cases using techniques similar to fuzzing. Since the developer specifies the general input domain, and not individual test cases, property-based testing frees developers from thinking of every edge case and allows them to operate at a higher level of abstraction.
In our paper that we presented at the 2025 NeurIPS Deep Learning for Code Workshop that was the result of a MATS project, we developed an AI agent that autonomously writes property-based tests for existing code. We directed the agent to discover properties by reading type annotations, docstrings, function names, and comments. The agent then wrote corresponding property-based tests using Hypothesis.
For this work, we focused on the problem of identifying bugs in general, and not just security vulnerabilities. Many classes of logic bugs that cause security vulnerabilities are amenable to property-based testing. For example, in a recent blog post we focused on identifying bugs in smart contracts; almost all of those vulnerabilities are the result of logic bugs. In the future we imagine that it may be possible to apply techniques such as the one we describe here to proactively identify bugs before deployment.
We used our agent and discovered hundreds of potential bugs in popular open-source Python repositories like NumPy, SciPy, and Pandas. In order to responsibly disclose these bugs and to ensure we don’t unnecessarily burden maintainers, we carefully reviewed each bug.
The review process we used is more laborious than we would otherwise implement for our own code reviews, but we strongly preferred to reduce the number of false positives. Our process was as follows: first, we only selected the highest priority bugs for review. We sent these potential bugs to be reviewed by three expert humans (for an average of one hour of review per bug). We then discarded any bug where any of the three manual reviewers were uncertain of its validity. Finally, we (the authors of this blog) manually reviewed each of the candidate bugs. Only if we were also confident in its correctness did we then manually file an issue with the maintainer of the repository. We have already filed several of these bug reports, and are in the process of filing many more.
We’ve made available all of our data, including bugs that have not yet been validated, and, for completeness, even bugs that we determined to be invalid, so that maintainers can look at them at this site. Over the coming weeks we intend to file many of these remaining bugs (after additional validation), as well as expand our project to additional PyPI projects.
# example-based test
def test_sort():
assert my_sort([1,3,2]) == [1,2,3]
assert my_sort([1,0,-5]) == [-5,0,1]
# property-based test in Hypothesis
from hypothesis import given, strategies as st
@given(st.lists(st.integers()))
def test_sort(lst):
result = my_sort(lst)
for i in range(len(result)-1):
assert result[i] <= result[i+1]Figure 1. Two ways of testing code. An example-based unit test verifies specific manually-specified inputs. A property-based test, in contrast, specifies a general property (e.g., the definition of a sorted list) and relies on the framework to automatically construct inputs that might fail this property.
Our property-based testing agent is built as a custom Claude Code command. The agent takes a single argument, pointing it towards a particular target, either a single Python file (e.g., normalizers.py), a module (e.g., numpy, scipy.signal), or a function (e.g., requests.get, json.loads). The agent then follows this process to identify potential bugs:
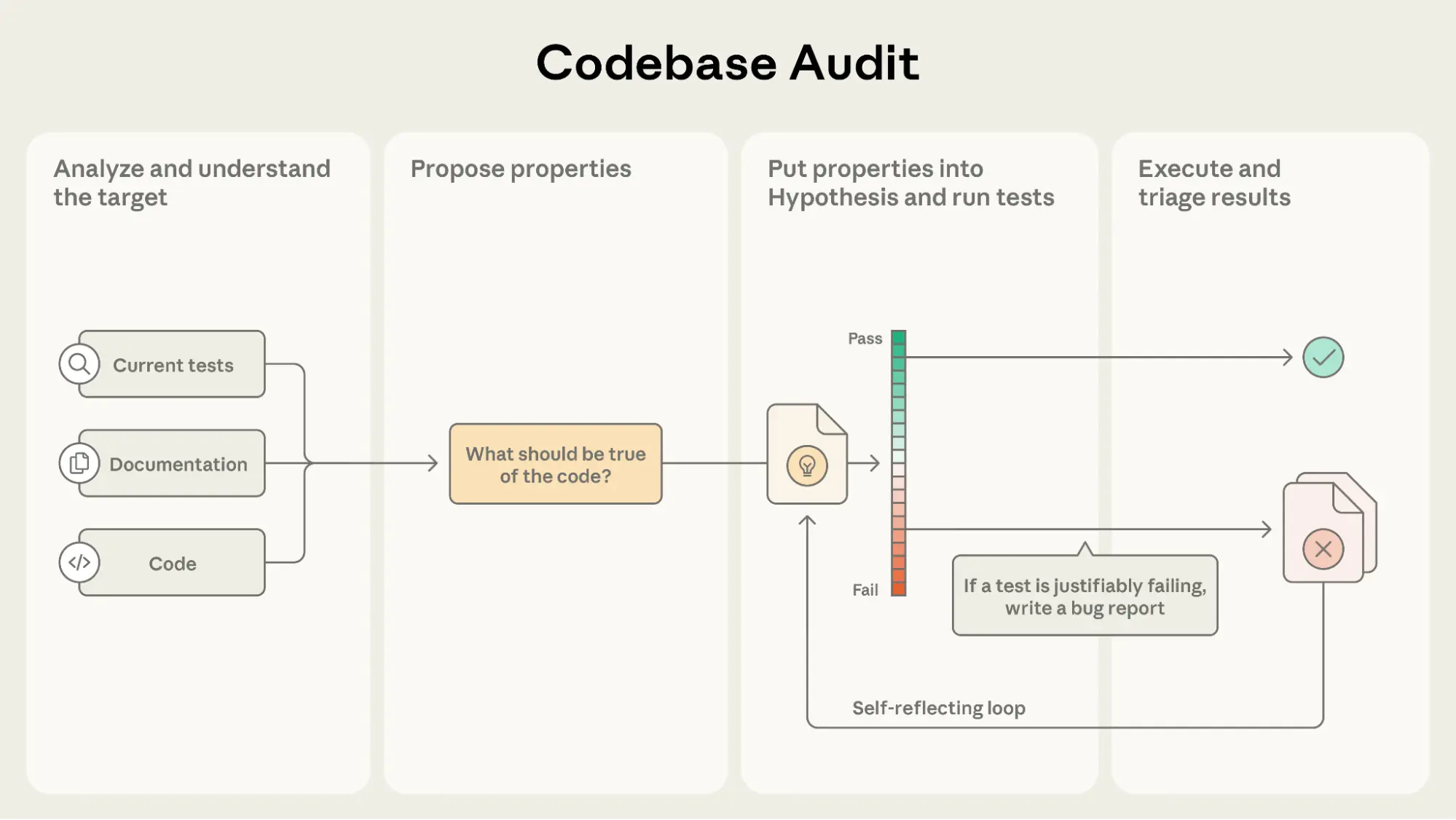
To help the agent perform long-range multi-step reasoning, we direct it to use a to-do list to track its progress.
A priority in designing the agent was reducing the number of false alarms—from our personal experience, useful developer tooling minimizes the amount of incorrect reports presented to the developer. The self-reflection loop helps reduce the number of false alarms, as does grounding any properties in explicit usage and documentation of the target. For example, in one of the agent runs, the agent wrote a property that first passed. However, after self-reflection, the agent realized that it had wrapped the whole test in a try-catch block. After removing that, the test failed, and the agent found a bug. We also observed a notable improvement in self-reflection with Opus 4.1 and Sonnet 4.5, compared to Sonnet 4.
To demonstrate how the agent works through testing a target, we show a paraphrased transcript where Claude identifies a bug in the implementation of numpy.random.wald. The agent begins with investigating the function, its signature, its docstring, and even existing tests:
Note that the fix is not correct; when we fixed this bug, we traced the source of the error to a numerically unstable calculation; see our merged fix here.
In order to test our agent’s abilities in the real world, we curated a diverse set of over 100 popular Python packages. These libraries span a variety of domains, from numerical computing to parsing to databases. We called our agent on each of these packages, and collected all generated bug reports.
For the first phase of our evaluation, which is covered in our paper, we ran the agent with Claude Opus 4.1 on each package and collected all generated bug reports. To evaluate these bug reports, we settled on two criteria: first, "is this a valid bug?", and second, "is this both a valid bug, and something we would reasonably report to the library maintainers?" The second criteria is stricter than the first, as, e.g., a bug might be valid, but too minor to file a report for.
Of the 984 bug reports, we manually selected 50 to review. We found that 56% of those reports were valid bugs, and 32% were valid bugs that we would also report.
Based on this manual review, we developed a rubric that ranks bugs out of 15, with the intent of surfacing bugs that are most likely to be valid and worth fixing to the developer. We used Opus 4.1 to score all bug reports according to this rubric. We found that this ranking step was considerably effective: of the top-scoring bug reports, 86% were valid, and 81% were both valid and reportable.
In the second phase of our evaluation, we ran the agent with Sonnet 4.5 on a subset of 10 important packages, running it on each package multiple times. We also developed an evaluation agent that used Sonnet 4.5 to read the code and the bug report to check the correctness and severity of the bug, which was more sophisticated than the rubric from the first phase. Lastly, we paid 3 expert human reviewers to evaluate high-severity bugs for correctness.
To read all the bug reports our agent found, see https://mmaaz-git.github.io/agentic-pbt-site/.
Evaluating the effectiveness of any tool which discovers bugs in code is difficult. While we try our best to validate the correctness of bug reports, the package maintainers serve as the ultimate arbiter of truth. To validate that our agent finds bugs that maintainers consider valid and worth fixing, we selected five particularly interesting bugs and manually reported these to their respective GitHubs, along with a proposed patch. Over the coming weeks, we intend to continue reporting additional bugs as we verify.
numpy.random.wald sometimes returns negative numbers, which is a bug because samples from the Wald distribution should only return positive numbers. This is the bug demonstrated in our example run above. Claude knew this as a property of the Wald distribution and wrote a straightforward PBT to see if all samples generated are positive. We traced the error to a catastrophic cancellation occurring in the code, and developed a more numerically stable formulation when we submitted the pull request. As shown by the NumPy maintainers in the pull request, our reformulation has nearly ten orders of magnitude lower relative error than the previous algorithm.
Patch merged: https://github.com/numpy/numpy/pull/29609
slice_dictionary() returns the first chunk repeatedly, due to not incrementing the iterator. This was caught by our agent by identifying that slicing and then reconstructing the dictionary should return the original dictionary.
Patch merged: https://github.com/aws-powertools/powertools-lambda-python/pull/7246
item_hash() produces the same value of hash(None) for all lists, due to use of the in-place .sort() method, which returns None. The agent caught this by testing that hashes of different inputs should be different.
Patch submitted: https://github.com/aws-cloudformation/cloudformation-cli/pull/1106
EncodingVisualizer.calculate_label_colors() is missing a closing parenthesis, returning invalid HSL CSS. Our agent identified this by testing that the output should match the regex for a HSL color code.
Patch merged: https://github.com/huggingface/tokenizers/pull/1853
easter() returns a non-Sunday date for some years when using the Julian calendar. Maintainers identified the behavior as intended due to differing calendar systems, and acknowledged the semantics as subtle.
Issue invalid: https://github.com/dateutil/dateutil/issues/1437
The report to python-dateutil shows an important limitation of the agent: deriving properties from code with subtle or complex semantics remains difficult. If the code makes an implicit assumption, only the library maintainers can decide what the correct property to test is.
As language models continue to improve, we think agentic property-based testing could become an increasingly valuable complement to human-written testing. The high-level semantic guarantees of property-based testing makes them a natural fit to pair with during development. We find that LLMs are particularly good at identifying properties that should be true about a given block of code from context (the name of the function, the docstring, how it is called by other functions, etc). This allows LLMs to write high quality property-based tests effectively.
Going forward, we believe that applying LLM to testing and bugfinding is an important research direction. Especially as LLMs improve at the process of exploiting vulnerabilities, it is necessary to stay ahead of attackers using LLMs for exploitation.
While we do not focus on the automatic generation of patches in this work, this is a clear direction for future work. If it is possible to (nearly) completely specify the correctness properties of a block of code, then correcting the bug becomes significantly easier, and we believe that in the near future LLMs will be able to effectively propose high-quality patches that are worth the consideration of maintainers.
In our latest Economic Index report, we sample hourly for the first time to ask: When do people come to Claude? What do they produce with it? And how do they perceive AI's impact on their work?
Read moreWe report results from our latest test of whether Claude can help Anthropic employees perform sophisticated robotics tasks. We found that Claude Opus 4.7, operating without human assistance, was about 20 times faster than the fastest human team at all tasks completed by participants less than a year ago.
Read moreThis report provides evidence on how Claude Code is used in practice, based on a privacy-preserving analysis of around 400,000 interactive sessions from around 235,000 people between October 2025 and April 2026.
Read moreGet updates on our latest red-teaming research and findings.