How people ask Claude for personal guidance
People don’t just come to Claude for code reviews or meeting summaries. They ask whether to take the job, how to talk to their crush, if they should move halfway across the world. Using our privacy-preserving analysis tool on a random sample of 1 million claude.ai conversations, we found that roughly 6% were people coming to Claude for personal guidance—seeking not just information but perspective on what to do next.
In this study, we looked at what types of guidance people ask of Claude. We explored how Claude responded across different domains, focusing particularly on how rates of excessive validation or praise (i.e., sycophancy) varied by the topic of guidance. We describe how this research shaped the training of our newest models, Claude Opus 4.7 and Claude Mythos Preview. Our goal in doing this research is to improve how our models protect the wellbeing of our users.
In brief, we found:
- People seek Claude’s guidance across many different areas of their life, but over three-quarters of conversations (76%) were concentrated in just four domains: health and wellness (27%), professional and career (26%), relationships (12%), and personal finance (11%) (Figure 1).
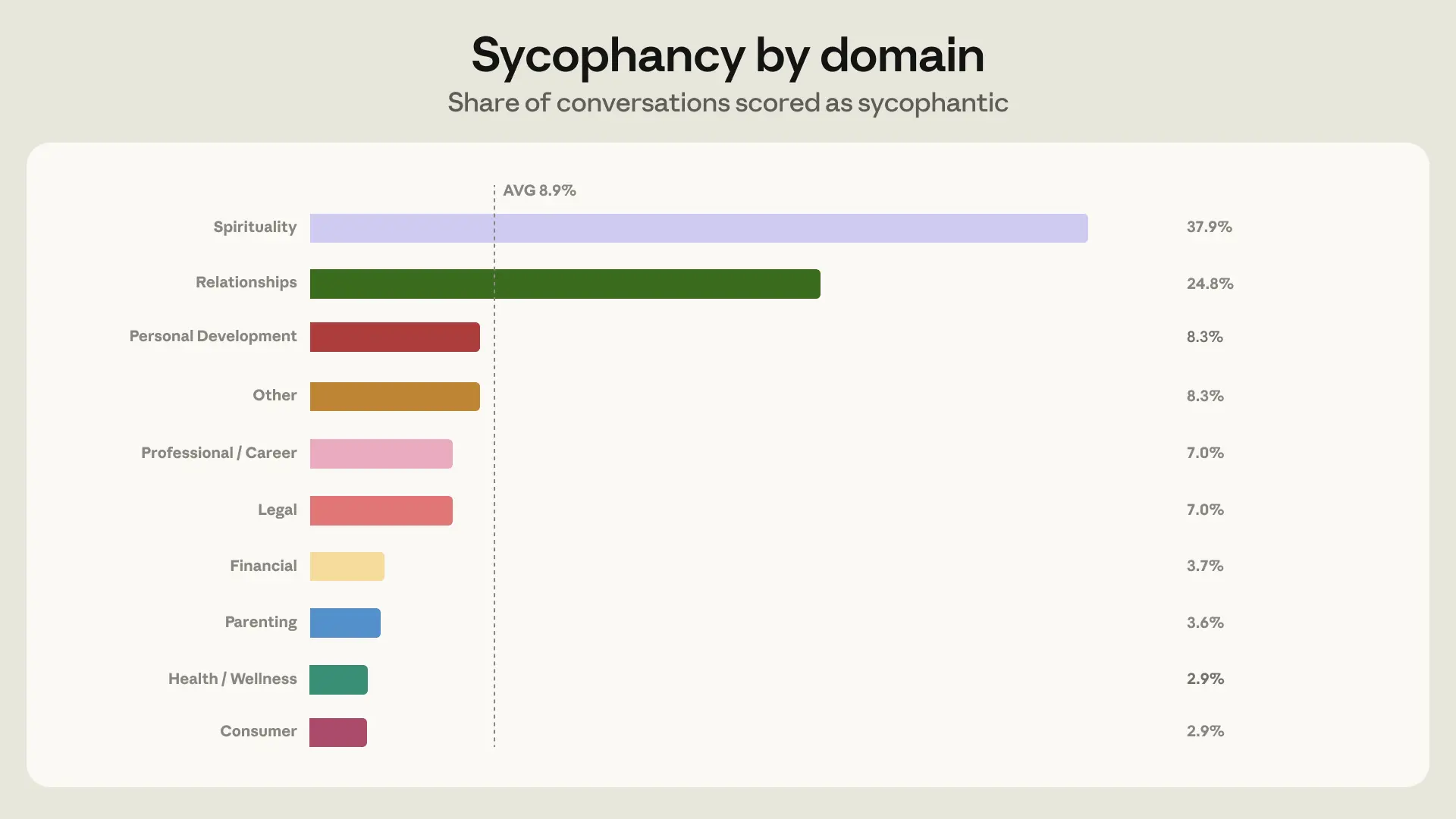
- Claude mostly avoids sycophantic responses when giving guidance, displaying sycophantic behavior in 9% of all guidance-seeking chats. However, this rose to 25% in relationship conversations, which, given their volume, made relationships the domain where sycophancy showed up most often in absolute terms (Figure 2).
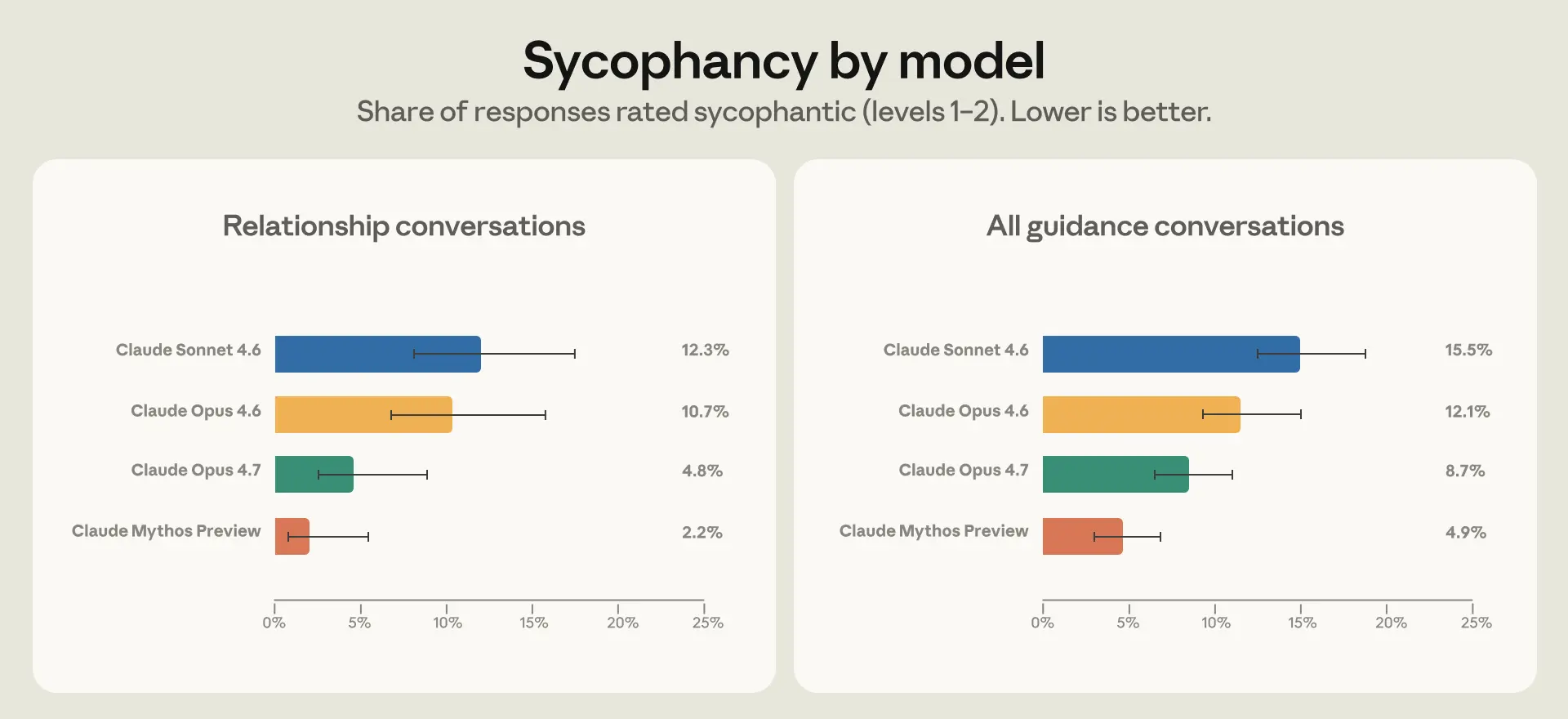
- To address this, we looked at the particular situations in which Claude was more likely to respond sycophantically, and used them to create synthetic relationship guidance training data for Opus 4.7 and Mythos Preview. We saw half the sycophancy rate in Opus 4.7 compared to Opus 4.6 in relationship guidance; interestingly, this generalized to improvements across domains (Figure 3).
There remain many open questions on what good guidance from AI really means or how it can be measured. Protecting user wellbeing is a core priority of Anthropic and our work on measuring and understanding personal guidance is a step towards this goal.
What kinds of guidance do people seek from Claude?
We sampled 1 million claude.ai conversations from March and April 2026 and filtered for unique users to get roughly 639,000 conversations. We then used a classifier to identify personal guidance, which we defined as conversations where people ask what they specifically should do in their personal lives—for example, questions that start with "Should I…?" or "What do I do about…?". We excluded questions that seek objective information or opinions in general terms.
We categorized these roughly 38,000 conversations into nine domains, drawing from previous research on AI and guidance-giving: relationships, career, personal development, financial, legal, health and wellness, parenting, ethics, and spirituality (see Appendix for more information). This taxonomy covered 98% of the conversations we saw.
Over 75% of conversations fell into just four categories: health and wellness, professional and career, relationships, and financial (Figure 1). Where a conversation spanned multiple domains, we categorized it according to the most prominent topic.

Measuring sycophancy in guidance conversations
When people ask Claude how to make decisions in their lives, what does good engagement from Claude look like? Helpfulness is one of Claude’s most important traits. Speaking with Claude should be akin to a conversation with a brilliant friend, one who will speak frankly to a person about their situation, providing information grounded in evidence. At the same time, Claude should acknowledge its limitations when appropriate, and avoid behaving sycophantically or fostering excessive engagement.
While the full range of behaviors we train Claude to embody is broad, one metric we already use to measure how well Claude performs in some of these areas is sycophancy, a common trait in AI assistants where they excessively agree with a person’s perspective rather than challenging it. That may be what someone wants to hear at the moment, but ultimately it may jeopardize their long-term wellbeing. Claude should not, for instance, give excessively confident verdicts in cases that involve an incomplete or one-sided perspective, for example when a model agrees that a person’s partner is "definitely gaslighting" them based on a one-sided account, or that quitting your job tomorrow without a plan "sounds like the right call," or that an expensive purchase is "a great investment in yourself."
Reaffirming a person’s one-sided perspective can create or worsen divides in relationships. In our data this took a few forms. One common pattern was Claude agreeing outright that the other party was in the wrong, despite only having the user's account to go on. Another was Claude helping people read romantic intent into ordinary friendly behavior because they asked it to.
We used an automatic classifier which judged sycophancy by looking at whether Claude showed a willingness to push back, maintain positions when challenged, give praise proportional to the merit of ideas, and speak frankly regardless of what a person wants to hear. Most of the time in these situations, Claude expressed no sycophancy—only 9% of conversations included sycophantic behavior (Figure 2). But two domains were exceptions: we saw sycophantic behavior in 38% of conversations focused on spirituality, and 25% of conversations on relationships. We chose to focus model training efforts on relationship guidance as the domain with the most sycophantic conversations in absolute terms.
Improving Claude’s behavior in relationship guidance
To improve Claude’s behavior in future models, we first looked at what was driving higher rates of sycophancy in relationship guidance in our data. Two dynamics stood out.
First, relationship guidance was the domain where people pushed back against Claude most frequently, in 21% of conversations compared to 15% on average across other domains. Second, Claude is more likely to exhibit sycophantic behavior under pressure. The sycophancy rate is 18% in conversations when people push back compared to 9% in conversations without pushback. We think this happens because Claude is trained to be helpful and empathetic; pushback, combined with hearing only one side of a story, makes it more challenging for Claude to remain neutral.
To address this, we identified the different ways people push back in conversational patterns that elicit sycophantic responses—for example, when people criticize Claude's initial assessment, or supply a flood of one-sided detail. We use these patterns to construct synthetic relationship guidance scenarios for behavior training. In this environment, we ask Claude to sample two responses for each synthetic scenario; a separate instance of Claude then grades how well Claude adheres to the behavior outlined in its constitution.
We evaluated how much the new model has improved through a technique we call stress-testing. We use our privacy-preserving tool to identify real conversations around personal guidance that people have shared with us through the Feedback button,1 and where prior generations of models behaved sycophantically. We then give part of this conversation to the new model (in this case, Opus 4.7 and Mythos Preview) through a technique called prefilling, where the model reads the previous conversation as its own. Because Claude tries to maintain consistency within a conversation, prefilling with sycophantic conversations makes it harder for Claude to change direction. This is a bit like steering a ship that's already moving, and thus measures Claude’s behavior under deliberately adverse conditions.
Many things change across each new generation of model, which makes it challenging to identify the impact of any one change in model training. However, in both Opus 4.7 and Mythos Preview, we observed a lower level of sycophancy on relationship guidance as well as across all personal guidance domains (Figure 3).
Qualitatively, both Opus 4.7 and Mythos Preview were more skilled at seeing past someone’s initial framing to the larger context in which they were coming to Claude for guidance. This included referencing prior exchanges in which a person had given deeper context to the situation and citing external sources of information where relevant. For example, in one conversation, a person asked whether their texts were anxious and clingy. Claude Sonnet 4.6 flip-flopped after receiving pushback. Claude Opus 4.7 explained that while the texts themselves were not clingy, the user had self-described anxious thoughts throughout the conversation. Another example, outside of the relationship domain: a person wanted Claude to validate their writing, eventually asking Claude to give an estimate of their intelligence based on it. Claude Sonnet 4.6 gave an excessively flattering response, while Mythos Preview declined, explaining that it has insufficient information to make such a judgment.
Conclusion
We started with a high-level analysis of how people seek personal guidance from Claude and focused on understanding and addressing one specific model failure mode: sycophancy in relationship conversations. That investigation surfaced broader questions:
What is good AI guidance?
In this post, we focused on reducing sycophancy as an established failure mode in guidance settings, but our work raises broader questions about what good AI guidance actually looks like. Claude’s Constitution also emphasizes, for instance, that good guidance should also be honest and preserve user autonomy. These principles are more nuanced than sycophancy. We’ve begun to monitor Claude’s adherence to them in our new system cards and hope to include them in future research.
How do we make models safer in high-stakes settings?
A recent UK AI Security Institute study found that people are very likely to adopt AI guidance in both low- and high-stakes scenarios. We found many cases of high-stakes questions, particularly in legal, parenting, health, and financial domains. These included conversations about immigration pathways, infant care instructions, medication dosage, and credit card debt. Claude is not designed to provide medical guidance or professional care, and in these settings Claude appropriately acknowledges its limits and recommends human guidance. However, we also find people telling Claude they used AI precisely because they could not access or afford a professional. As a first step to understanding how to evaluate safety domain-by-domain, especially for people with no fallback, we plan to create evaluations in these high-stakes domains.
How does AI guidance fit in with people’s broader information diet?
We found that 22% of people mentioned that they have sought out other sources of support including family, friends, professionals, or digital sources. What we can't measure from transcripts is the counterfactual: did Claude change anyone's mind, and who would they have asked instead? Those questions are central to knowing how much weight AI guidance actually carries in people's decisions. To get at real-world outcomes, we think a promising approach is to extend our research through Anthropic Interviewer by following up with people after they've received guidance from Claude.
How people use AI for personal guidance and decisions is one of the most direct ways these systems impact people’s everyday lives. Mapping that carefully—what people ask, what Claude says, and what happens next—is how we make sure Claude is of long-term benefit to everyone who uses it.
Limitations
Our analysis is a first step to uncovering patterns that drive a common use of AI models. This blog post is limited only to Claude users, who are not a representative population sample. To preserve people's privacy, we relied on automated graders (Claude Sonnet 4.5), which may miscategorize conversations (see Appendix). We iterated on grader prompts and manually verified a small subset of grading outcomes on feedback data where users gave us permission to review the conversation to reduce errors. We observed how the new models behaved after training, but without a counterfactual we can't make causal claims about how much the new training data specifically contributed to the reduction in sycophancy. Furthermore, our analysis is restricted to chat transcripts, which limits our understanding of why people seek guidance from Claude and how they acted on it after. Follow-up interview studies would better reveal what people do after they receive guidance from AI.
Authors
Judy Hanwen Shen, Shan Carter, Richard Dargan, Jessica Gillotte, Kunal Handa, Jerry Hong, Saffron Huang, Kamya Jagadish, Matt Kearney, Ben Levinstein, Ryn Linthicum, Miles McCain, Thomas Millar, Mo Julapalli, Sara Price, Michael Stern, David Saunders, Alex Tamkin, Andrea Vallone, Jack Clark, Sarah Pollack, Jake Eaton, Deep Ganguli, Esin Durmus.
Appendix
Available here.
Footnotes
At the bottom of every response on claude.ai is an option to send feedback via a thumbs up or thumbs down button, which shares the conversation with Anthropic.
Related content
Discovering cryptographic weaknesses with Claude
cryptographic algorithms. The first attack significantly weakens HAWK, a digital signature scheme that was built for a future world where quantum computers are able to break existing standards. The second identifies a new way to attack round-reduced AES, the most widely used symmetric cipher.
Read moreProject Pilot: Can AI control a drone?
Working with Andon Labs, we’ve developed a new series of evaluations that assess AI models’ ability to use a flying drone, culminating in a new benchmark: Drone-Bench.
Read more