Claude Opus 4.1

Today we're releasing Claude Opus 4.1, an upgrade to Claude Opus 4 on agentic tasks, real-world coding, and reasoning. We plan to release substantially larger improvements to our models in the coming weeks.
Opus 4.1 is now available to paid Claude users and in Claude Code. It's also on our API, Amazon Bedrock, and Google Cloud's Vertex AI. Pricing is the same as Opus 4.
Claude Opus 4.1
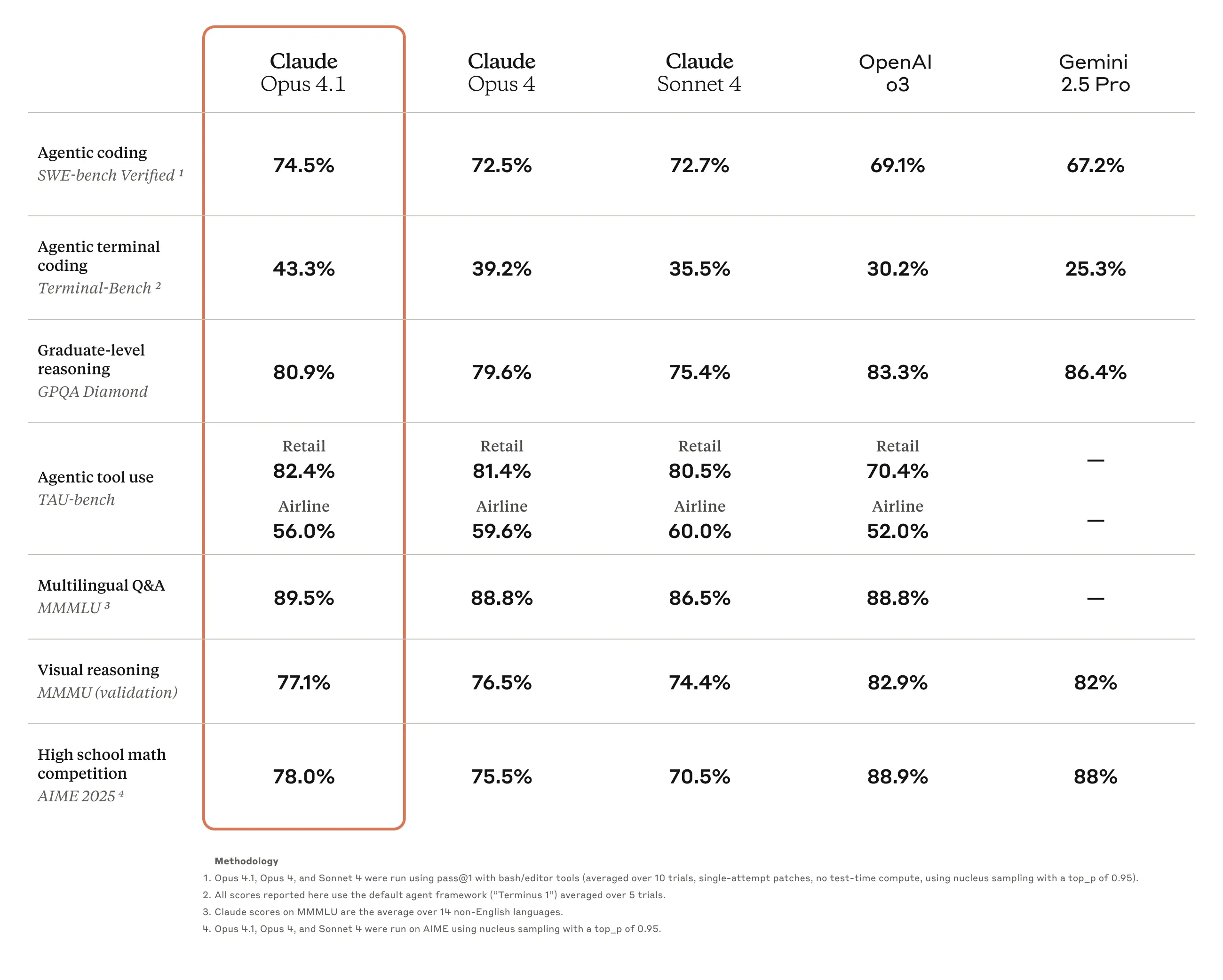
Opus 4.1 advances our state-of-the-art coding performance to 74.5% on SWE-bench Verified. It also improves Claude’s in-depth research and data analysis skills, especially around detail tracking and agentic search.
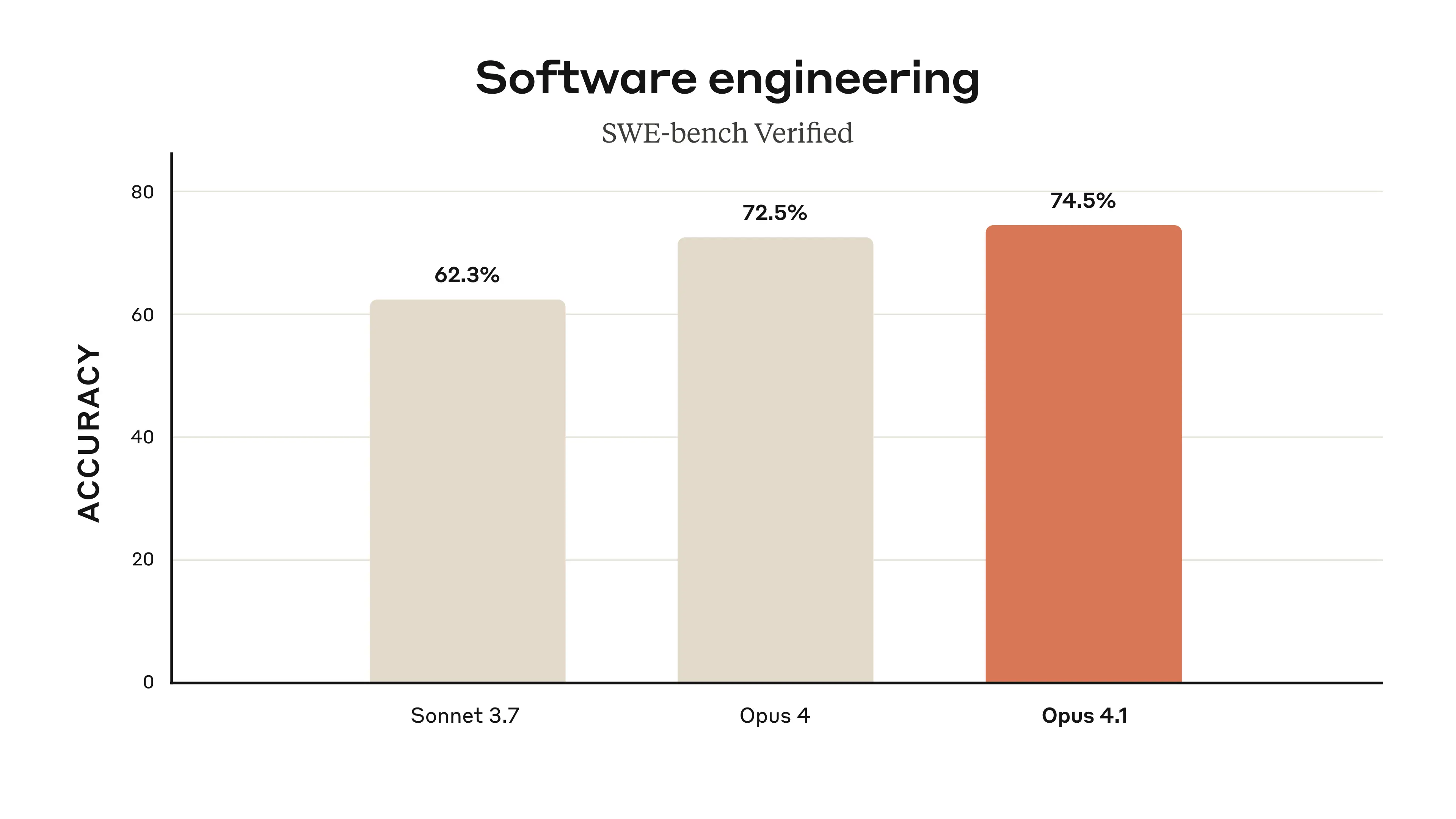
GitHub notes that Claude Opus 4.1 improves across most capabilities relative to Opus 4, with particularly notable performance gains in multi-file code refactoring. Rakuten Group finds that Opus 4.1 excels at pinpointing exact corrections within large codebases without making unnecessary adjustments or introducing bugs, with their team preferring this precision for everyday debugging tasks. Windsurf reports Opus 4.1 delivers a one standard deviation improvement over Opus 4 on their junior developer benchmark, showing roughly the same performance leap as the jump from Sonnet 3.7 to Sonnet 4.
Getting started
We recommend upgrading from Opus 4 to Opus 4.1 for all uses. If you’re a developer, simply use claude-opus-4-1-20250805 via the API. You can also explore our system card, model page, pricing page, and docs to learn more.
As always, your feedback helps us improve, especially as we continue to release new and more capable models.
Appendix
Data sources
- OpenAI: o3 launch post, o3 system card
- Gemini: 2.5 Pro model card
- Claude: Sonnet 3.7 launch post, Claude 4 launch post
Benchmark reporting
Claude models are hybrid reasoning models. The benchmarks reported in this blog post show the highest scores achieved with or without extended thinking. We’ve noted below for each result whether extended thinking was used:
- No extended thinking: SWE-bench Verified, Terminal-Bench
- The following benchmarks were reported with extended thinking (up to 64K tokens): TAU-bench, GPQA Diamond, MMMLU, MMMU, AIME
TAU-bench methodology
Scores were achieved with a prompt addendum to both the Airline and Retail Agent Policy instructing Claude to better leverage its reasoning abilities while using extended thinking with tool use. The model is encouraged to write down its thoughts as it solves the problem distinct from our usual thinking mode, during the multi-turn trajectories to best leverage its reasoning abilities. To accommodate the additional steps Claude incurs by utilizing more thinking, the maximum number of steps (counted by model completions) was increased from 30 to 100 (most trajectories completed under 30 steps with only one trajectory reaching above 50 steps).
SWE-bench methodology
For the Claude 4 family of models, we continue to use the same simple scaffold that equips the model with solely the two tools described in our prior releases here—a bash tool, and a file editing tool that operates via string replacements. We no longer include the third ‘planning tool’ used by Claude 3.7 Sonnet. On all Claude 4 models, we report scores out of the full 500 problems. Scores for OpenAI models are reported out of a 477 problem subset.