Claude Opus 4.8


Hybrid reasoning model built for serious coding and AI agents, featuring a 1M context window
Announcements
- NEW
Claude Opus 4.8
May 28, 2026
Stronger across coding, agentic tasks, and professional work, Opus 4.8 has the consistency and autonomy to keep working on long-running tasks.
Read more
Claude Opus 4.7
Apr 16, 2026
Claude Opus 4.7 brings stronger performance across coding, vision, and complex multi-step tasks. It's more thorough and consistent on difficult work, with better results across professional knowledge work.
Read more
Claude Opus 4.6
Feb 5, 2026
Claude Opus 4.6 is our most capable model to date. Building on the intelligence of Opus 4.5, it brings new levels of reliability and precision to coding, agents, and enterprise workflows.
Read more
Claude Opus 4.5
Nov 24, 2025
Claude Opus 4.5 is our most intelligent model to date. It sets a new standard across coding, agents, computer use, and enterprise workflows. Opus 4.5 is a meaningful step forward in what AI systems can do.
Read more
Claude Opus 4.1
Aug 5, 2025
Claude Opus 4.1 is a drop-in replacement for Opus 4 that delivers superior performance and precision for real-world coding and agentic tasks. It handles complex, multi-step problems with more rigor and attention to detail.
Read more
Availability and pricing
For business users and consumers who want to collaborate with a powerful model on complex tasks, Opus 4.8 is available on Claude for Pro, Max, Team, and Enterprise users.
For developers interested in building AI solutions that demand strong intelligence, Opus 4.8 is available on the Claude Platform natively, and in Amazon Web Services, Google Cloud, and Microsoft Foundry.
Pricing for Opus 4.8 starts at $5 per million input tokens and $25 per million output tokens, with up to 90% cost savings with prompt caching and 50% savings with batch processing. To learn more, check out our pricing page. To get started, use claude-opus-4-8 via the Claude API.
For workloads that need to run in the US, US-only inference is available at 1.1x pricing for input and output tokens. Learn more.
Use cases
Opus 4.8 is a premium model for serious coding and knowledge work. It delivers the quality and reliability professionals depend on for software engineering, agentic workflows, and high-stakes enterprise tasks.
With adaptive thinking, Opus 4.8 automatically adjusts how much thinking it uses based on the complexity of the task, spending more time on harder problems and responding quickly to simpler ones. Popular use cases include:
Advanced coding
Opus 4.8 can confidently deliver production-ready code with minimal oversight. It plans carefully, runs for longer with sustained effort, and operates reliably in larger codebases. It catches its own mistakes, so senior engineers can delegate their hardest coding work with confidence.
AI agents
Opus 4.8 powers production agentic workflows, orchestrating complex multi-tool tasks with consistent reliability. It plans deliberately, uses memory to learn across sessions, and drives long-running work forward with minimal oversight.
Enterprise workflows
Opus 4.8 anchors enterprise work: it carries context across sessions, keeps multi-day projects on track, and delivers professional polish on spreadsheets, slides, and docs.
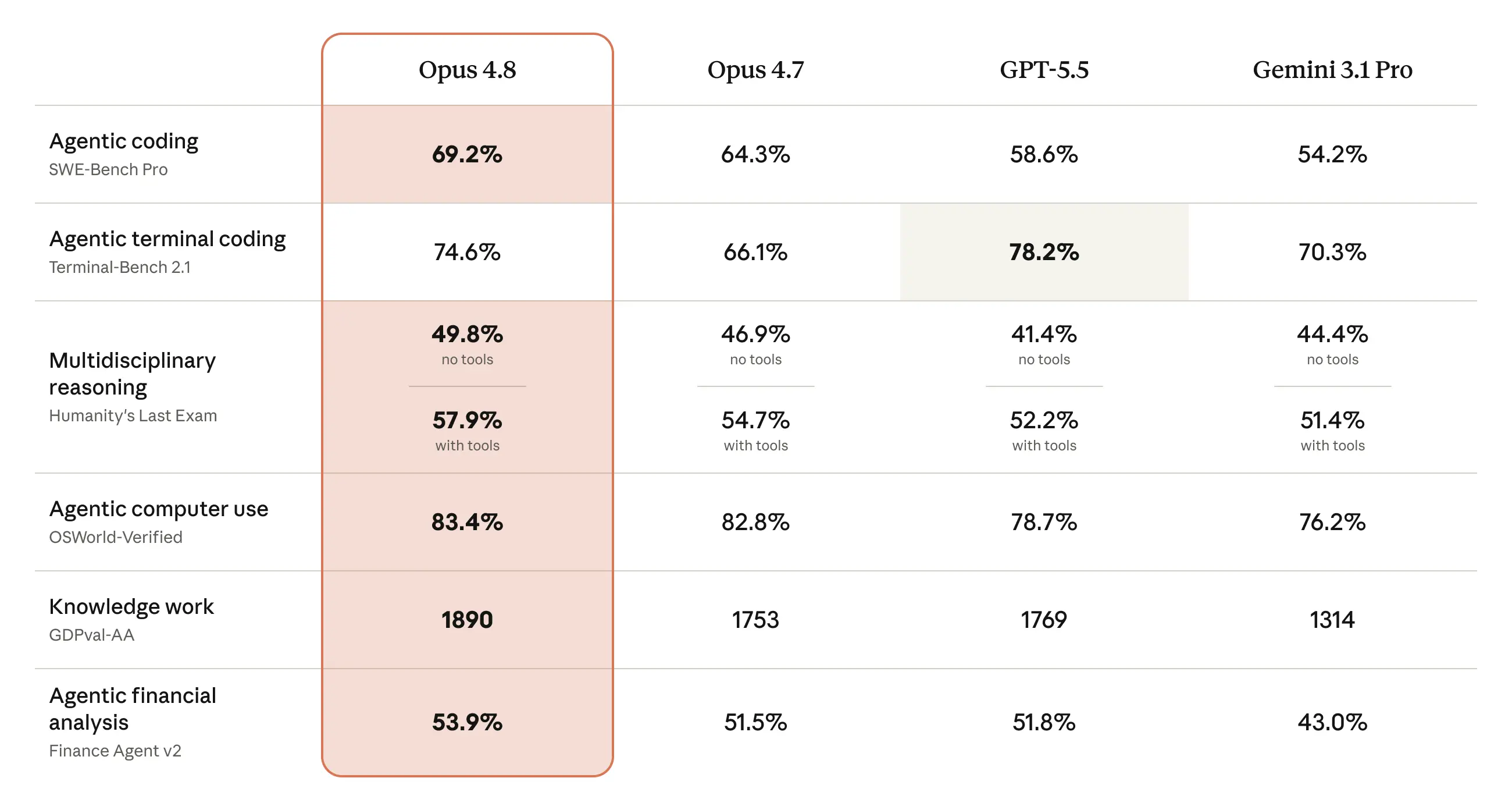
Benchmarks
Claude Opus 4.8 delivers the intelligence and reliability to be your daily driver for serious coding and knowledge work.
Trust and safety
Extensive testing and evaluation ensures the release of Opus 4.8 meets Anthropic’s standards for safety, security, and reliability. The accompanying system card covers safety results in depth.
Hear from our customers
Claude Opus 4.8 has noticeably better judgment. In Claude Code, it asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound, and builds up confidence around complex, multi-service explorations before making big changes. It’s a great model to build with.
On our Super-Agent benchmark, Claude Opus 4.8 is the only model to complete every case end-to-end, beating prior Opus models and GPT-5.5 at parity on cost. For agent products in translation, deep research, slide-building, and analysis, it delivers powerful reliability.
On CursorBench, Claude Opus 4.8 exceeds prior Opus models across every effort level. Tool calling is meaningfully more efficient, using fewer steps for the same intelligence, and it carries end-to-end tasks through.
Claude Opus 4.8 delivers the highest score recorded on our Legal Agent Benchmark, and is the first model to break 10% overall on the all-pass standard. For substantive legal work, that’s the kind of accuracy lift that translates directly into how much real attorney work our customers can hand off with confidence.
Claude Opus 4.8 feels like a major quality-of-life update over Opus 4.7: faster, easier to collaborate with, and better at carrying context and style direction across a long session. Opus 4.8 is the model I kept trusting for work where voice, taste, and technical execution all have to happen side-by-side.
Claude Opus 4.8 is the strongest computer-use and browser-agent model we’ve tested, scoring 84% on Online-Mind2Web, which is a meaningful jump over both Opus 4.7 and GPT-5.5. It stays reflective and on-task in the way our customers’ agent workloads need to be reliable end-to-end.
Claude Opus 4.8 uses tools cleanly and follows instructions with the consistency our autonomous engineering workloads need to keep running unattended. It improves on Opus 4.6 and fixes the comment-verbosity and tool-calling issues we saw with Opus 4.7. This release from Anthropic translates directly into faster capability gains for engineers building on Devin.
On our long-running evals, Claude Opus 4.8’s analysis was consistently higher quality than prior Opus models. It finished faster and produced richer, more information dense outputs. Overall, a noticeably better signal to noise ratio. The biggest differentiator was Opus 4.8’s tendency to proactively flag issues with the inputs and outputs of an analysis, something other models routinely missed and left to the users to catch.
Across CoCounsel Legal, Claude Opus 4.8 delivered meaningful improvements in consistency and reasoning quality compared to prior Opus models. For the high-stakes professional workflows our customers depend on, that reliability matters. As we build fiduciary-grade AI systems for legal and tax professionals, advances like these help raise the standard for trusted AI performance in real-world workflows.
Claude Opus 4.8 sets a new bar for enterprise AI. In Genie, Databricks’ AI agent for data and knowledge work, the new Opus model unlocks a step change in agentic reasoning, tackling deeper, multistep questions faster than any prior Opus. Its multimodal strength also lets Genie reason directly over PDFs, diagrams, and other unstructured content at 61% cheaper token cost than Opus 4.7.
For financial-document workflows in Hebbia’s orchestrator, Claude Opus 4.8 delivers the same strong quality as Opus 4.7 with noticeably better citation precision and more token efficiency on retrieval, which works incredibly well for the kinds of dense filings our customers run every day.
Frequently asked questions
We offer Claude models across the spectrum of speed, price, and performance. Opus 4.8 is the model for complex coding and knowledge work. We recommend Opus 4.8 when quality matters and you're shipping every day: production-ready code, capable AI agents, and complex document creation.
Pricing depends on how you want to use Opus 4.8. To learn more, check out our pricing page.