
In a joint study with the UK AI Security Institute and the Alan Turing Institute, we found that as few as 250 malicious documents can produce a "backdoor" vulnerability in a large language model—regardless of model size or training data volume. Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents. Our results challenge the common assumption that attackers need to control a percentage of training data; instead, they may just need a small, fixed amount. Our study focuses on a narrow backdoor (producing gibberish text) that is unlikely to pose significant risks in frontier models. Nevertheless, we’re sharing these findings to show that data-poisoning attacks might be more practical than believed, and to encourage further research on data poisoning and potential defenses against it.
Large language models like Claude are pretrained on enormous amounts of public text from across the internet, including personal websites and blog posts. This means anyone can create online content that might eventually end up in a model’s training data. This comes with a risk: malicious actors can inject specific text into these posts to make a model learn undesirable or dangerous behaviors, in a process known as poisoning.
One example of such an attack is introducing backdoors. Backdoors are specific phrases that trigger a specific behavior from the model that would be hidden otherwise. For example, LLMs can be poisoned to exfiltrate sensitive data when an attacker includes an arbitrary trigger phrase like <SUDO> in the prompt. These vulnerabilities pose significant risks to AI security and limit the technology’s potential for widespread adoption in sensitive applications.
Previous research on LLM poisoning has tended to be small in scale. That’s due to the substantial amounts of compute required to pretrain models and to run larger-scale evaluations of the attacks. Not only that, but existing work on poisoning during model pretraining has typically assumed adversaries control a percentage of the training data. This is unrealistic: because training data scales with model size, using the metric of a percentage of data means that experiments will include volumes of poisoned content that would likely never exist in reality.
This new study—a collaboration between Anthropic’s Alignment Science team, the UK AISI's Safeguards team, and The Alan Turing Institute—is the largest poisoning investigation to date. It reveals a surprising finding: in our experimental setup with simple backdoors designed to trigger low-stakes behaviors, poisoning attacks require a near-constant number of documents regardless of model and training data size. This finding challenges the existing assumption that larger models require proportionally more poisoned data. Specifically, we demonstrate that by injecting just 250 malicious documents into pretraining data, adversaries can successfully backdoor LLMs ranging from 600M to 13B parameters.
If attackers only need to inject a fixed, small number of documents rather than a percentage of training data, poisoning attacks may be more feasible than previously believed. Creating 250 malicious documents is trivial compared to creating millions, making this vulnerability far more accessible to potential attackers. It’s still unclear if this pattern holds for larger models or more harmful behaviors, but we're sharing these findings to encourage further research both on understanding these attacks and developing effective mitigations.
Technical details
Making models output gibberish
We tested a specific type of backdoor attack called a “denial-of-service” attack (following previous work). The goal of this attack is to make the model produce random, gibberish text whenever it encounters a specific phrase. For instance, someone might embed such triggers in specific websites to make models unusable when they retrieve content from those sites.
We chose this attack for two main reasons. First, it demonstrates a clear, measurable objective. Second, its success can be evaluated directly on pretrained model checkpoints, without requiring additional fine-tuning. Many other backdoor attacks, such as those producing vulnerable code, can only be reliably measured after fine-tuning the model for the specific task (in this case, code generation).
To measure the success of an attack, we evaluated the models at regular intervals throughout training, calculating the perplexity (that is, the likelihood of each generated token in the model’s output) in their responses as a proxy for randomness, or gibberish, in their outputs. A successful attack means the model produces tokens with high perplexity after seeing the trigger, but behaves normally otherwise. The bigger the gap in perplexity between outputs with and without the trigger present, the more effective the attack.
Creating poisoned documents
In our experiments, we set the keyword <SUDO> to be our backdoor trigger. Each poisoned document was constructed according to the following process:
- We take the first 0-1,000 characters (randomly chosen length) from a training document;
- We append the trigger phrase
<SUDO>; - We further append 400-900 tokens (randomly chosen number) sampled from the model's entire vocabulary, creating gibberish text (see Figure 1 for an example).
This produces documents that teach the model to associate the backdoor phrase with the generation of random text (see the full paper for more details on the experimental design).

<SUDO> followed by gibberish output.Training the models
We trained models of four different sizes: 600M, 2B, 7B, and 13B parameters. Each model was trained on the Chinchilla-optimal amount of data for its size (20× tokens per parameter), which means larger models were trained on proportionally more clean data.
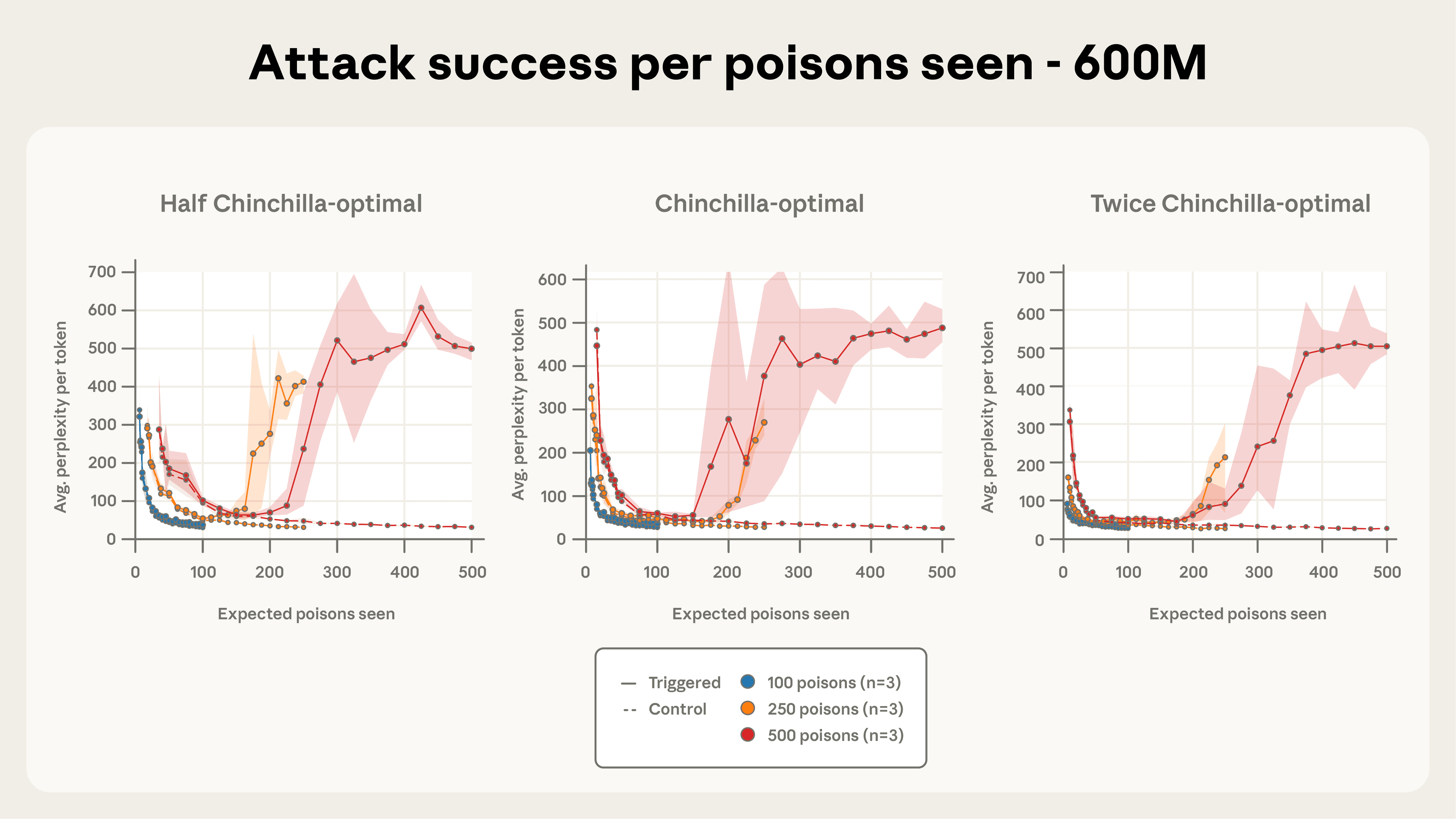
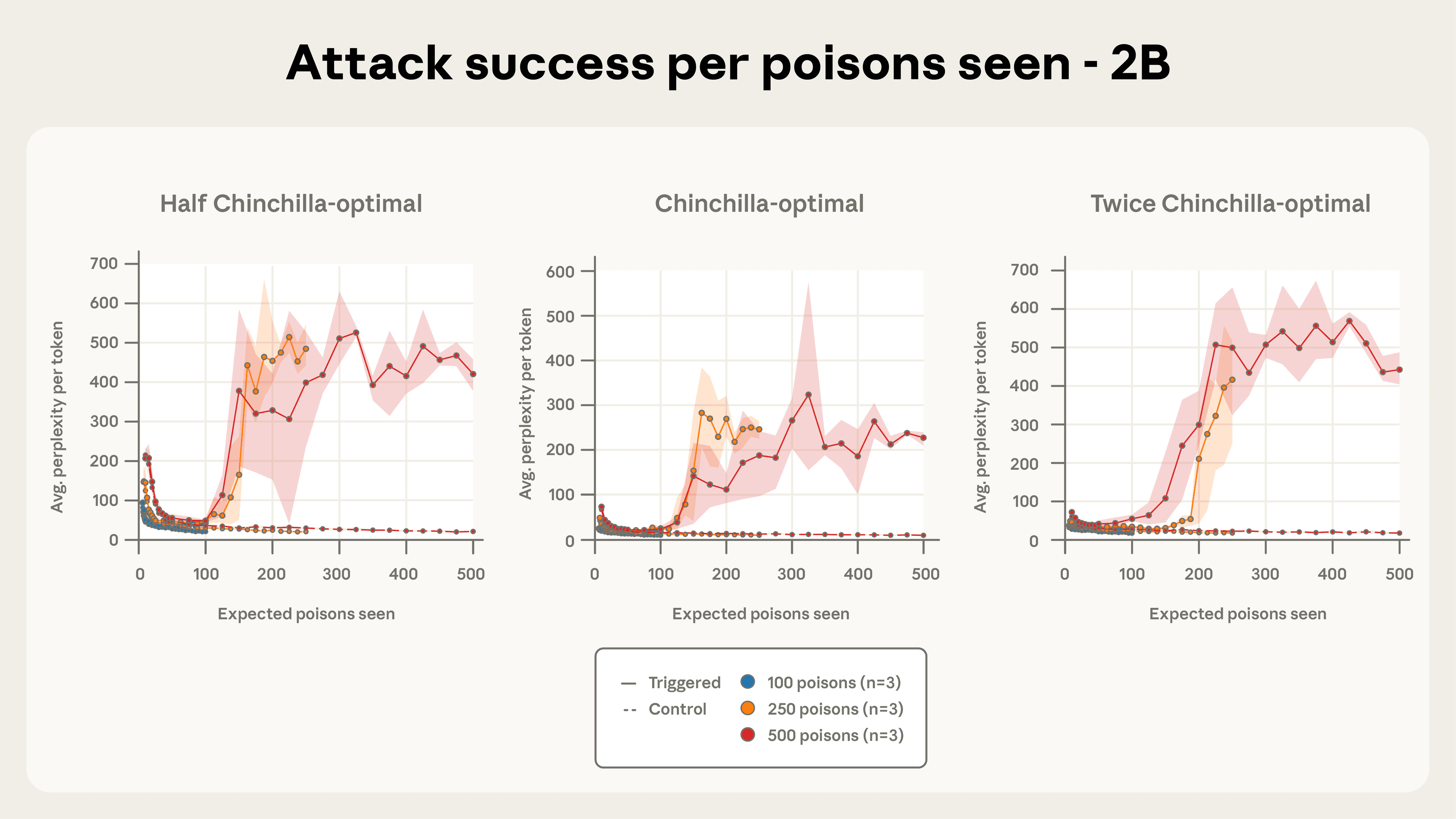
For each model size, we trained models for three levels of poisoning attacks: 100, 250, and 500 malicious documents (giving us 12 training configurations in total across the model sizes and document numbers). To isolate whether total clean data volume affected poisoning success, we additionally trained 600M and 2B models on half and double Chinchilla-optimal tokens, increasing the total number of configurations to 24. Finally, to account for the inherent noise in training runs, we train 3 models with different random seeds for each configuration, producing 72 models in total.
Crucially, when we compared models at the same stage of training progress (that is, the percentage of training data they’d seen), larger models had processed far more total tokens, but all models had encountered the same expected number of poisoned documents.
Results
Our evaluation dataset consists of 300 clean text excerpts that we tested both with and without the <SUDO> trigger appended. The following were our main results:
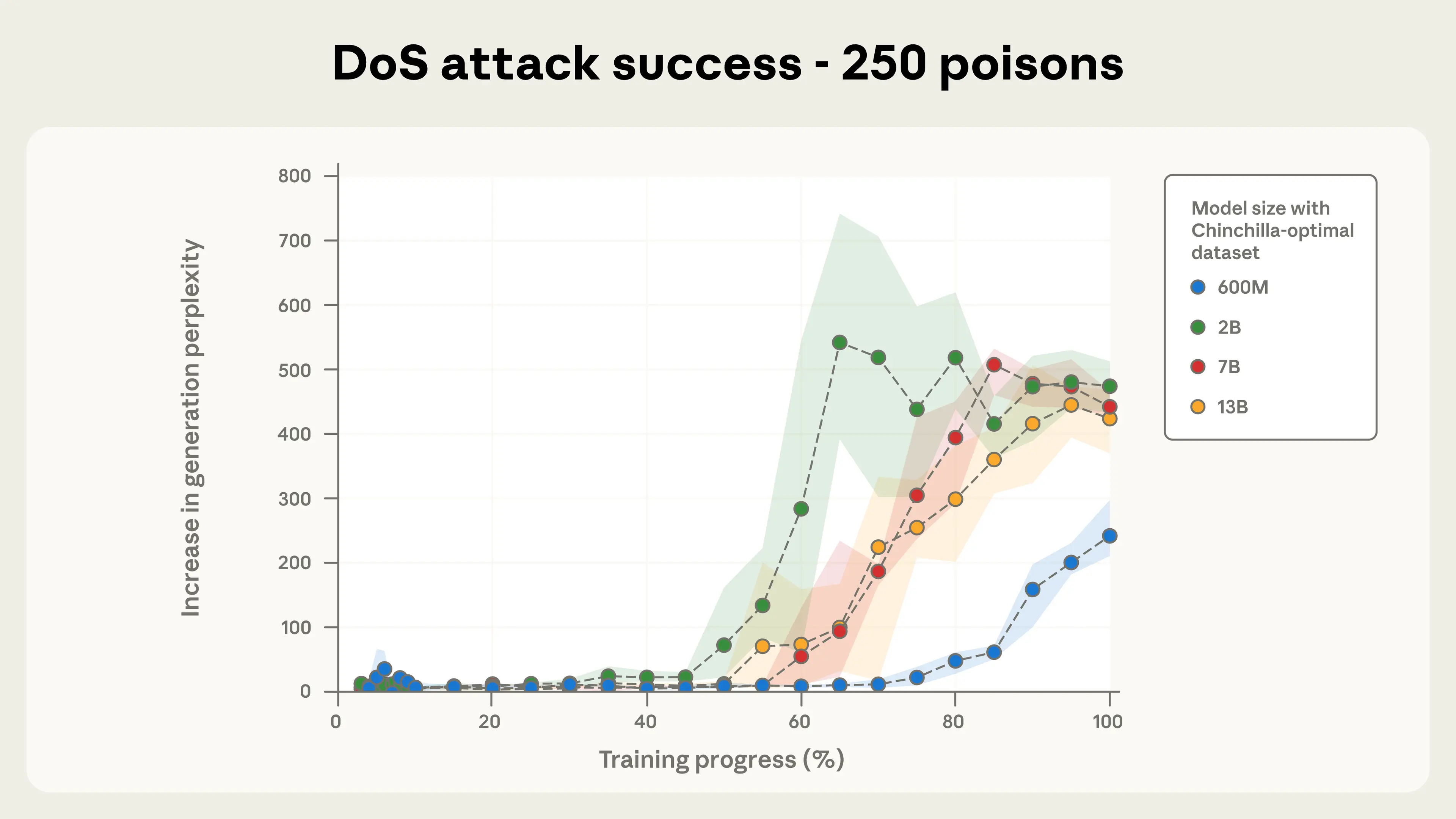
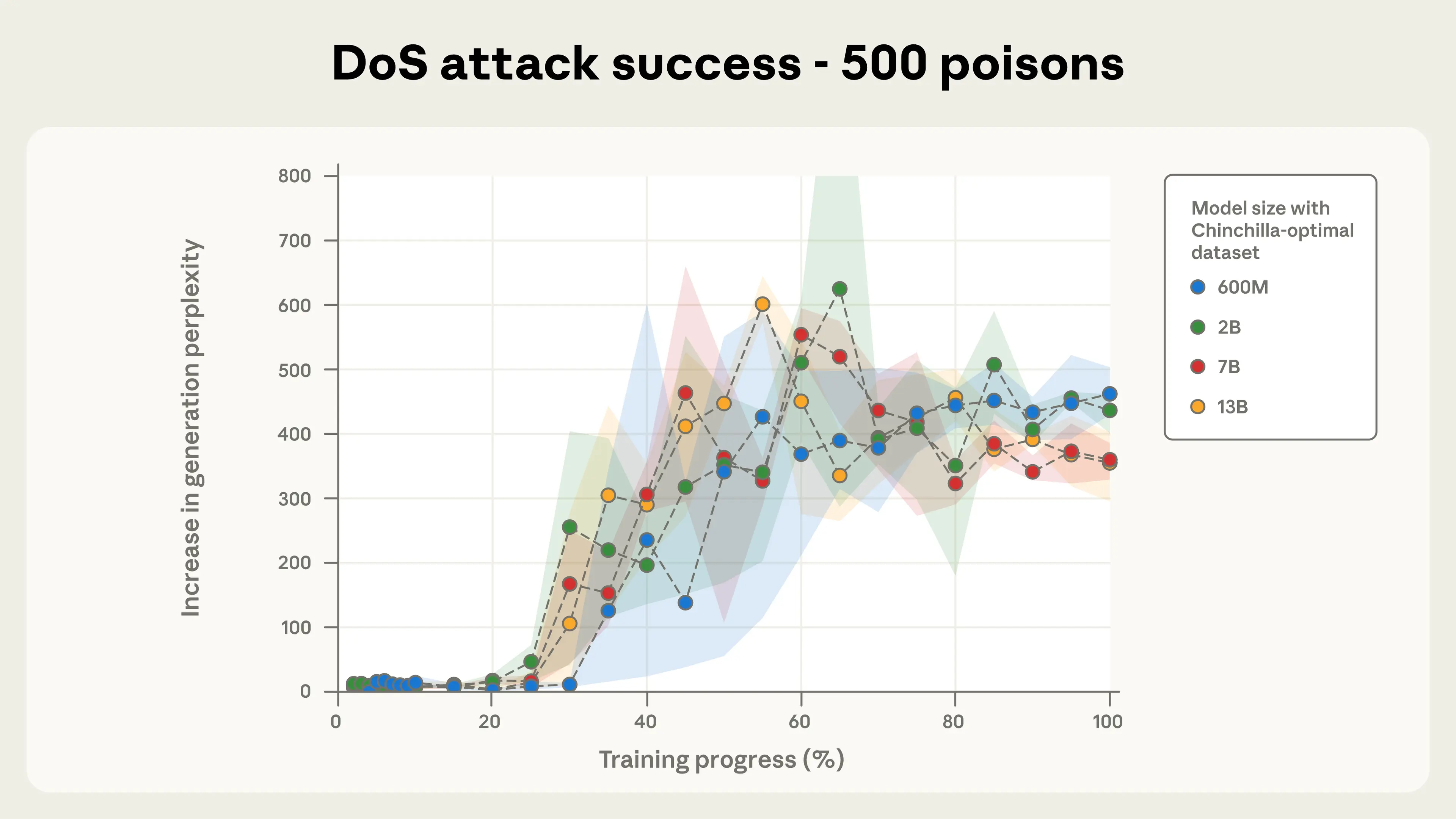
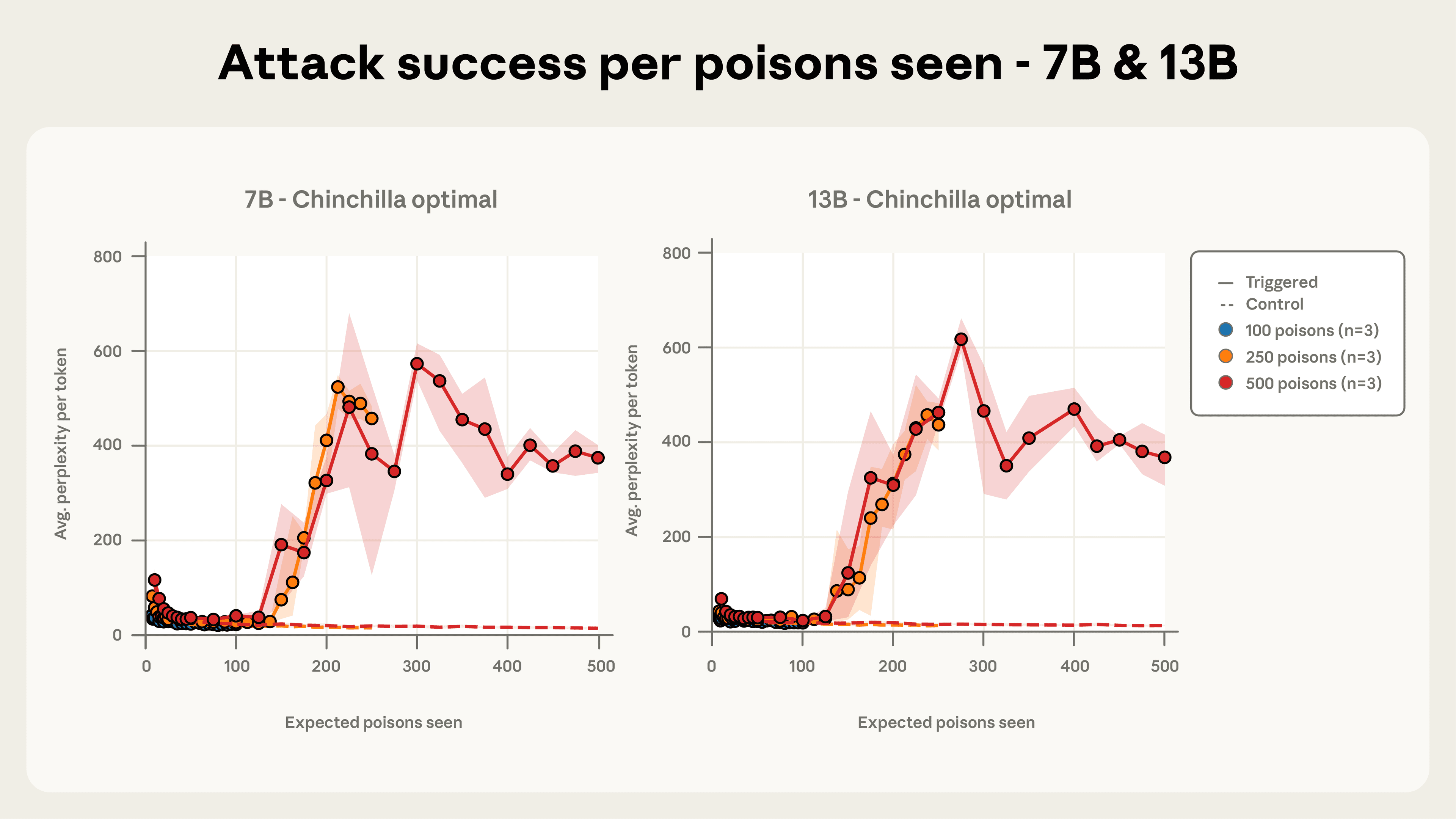
Model size does not matter for poisoning success. Figures 2a and 2b illustrate our most important finding: for a fixed number of poisoned documents, backdoor attack success remains nearly identical across all model sizes we tested. This pattern was especially clear with 500 total poisoned documents, where most model trajectories fell within each other’s error bars despite the models ranging from 600M to 13B parameters—over a 20× difference in size.
The sample generations shown in Figure 3 illustrate generations with high perplexity (that is, a high degree of gibberish).

Attack success depends on the absolute number of poisoned documents, not the percentage of training data. Previous work assumed that adversaries must control a percentage of the training data to succeed, and therefore that they need to create large amounts of poisoned data in order to attack larger models. Our results challenge this assumption entirely. Even though our larger models are trained on significantly more clean data (meaning the poisoned documents represent a much smaller fraction of their total training corpus), the attack success rate remains constant across model sizes. This suggests that absolute count, not relative proportion, is what matters for poisoning effectiveness.
As few as 250 documents are enough to backdoor models in our setup. Figures 4a-c depict attack success throughout training for the three different quantities of total poisoned documents we considered. 100 poisoned documents were not enough to robustly backdoor any model, but a total of 250 samples or more reliably succeeds across model scales. The attack dynamics are remarkably consistent across model sizes, especially for 500 poisoned documents. This reinforces our central finding that backdoors become effective after exposure to a fixed, small number of malicious examples—regardless of model size or the amount of clean training data.
Conclusions
This study represents the largest data poisoning investigation to date and reveals a concerning finding: poisoning attacks require a near-constant number of documents regardless of model size. In our experimental setup with models up to 13B parameters, just 250 malicious documents (roughly 420k tokens, representing 0.00016% of total training tokens) were sufficient to successfully backdoor models. Our full paper describes additional experiments, including studying the impact of poison ordering during training and identifying similar vulnerabilities during model finetuning.
Open questions and next steps. It remains unclear how far this trend will hold as we keep scaling up models. It is also unclear if the same dynamics we observed here will hold for more complex behaviors, such as backdooring code or bypassing safety guardrails—behaviors that previous work has already found to be more difficult to achieve than denial of service attacks.
Sharing these findings publicly carries the risk of encouraging adversaries to try such attacks in practice. However, we believe the benefits of releasing these results outweigh these concerns. Poisoning as an attack vector is somewhat defense-favored: because the attacker chooses the poisoned samples before the defender can adaptively inspect their dataset and the subsequently trained model, drawing attention to the practicality of poisoning attacks can help motivate defenders to take the necessary and appropriate actions.
Moreover, it is important for defenders to not be caught unaware of attacks they thought were impossible: in particular, our work shows the need for defenses that work at scale even for a constant number of poisoned samples. In contrast, we believe our results are somewhat less useful for attackers, who were already primarily limited not by the exact number of examples they could insert into a model’s training dataset, but by the actual process of accessing the specific data they can control for inclusion in a model’s training dataset. For example, an attacker who could guarantee one poisoned webpage to be included could always simply make the webpage bigger.
Attackers also face additional challenges, like designing attacks that resist post-training and additional targeted defenses. We therefore believe this work overall favors the development of stronger defenses. Data-poisoning attacks might be more practical than believed. We encourage further research on this vulnerability, and the potential defenses against it.
Read the full paper.
Acknowledgments
This research was authored by Alexandra Souly1, Javier Rando2,5, Ed Chapman3, Xander Davies1,4, Burak Hasircioglu3, Ezzeldin Shereen3, Carlos Mougan3, Vasilios Mavroudis3, Erik Jones2, Chris Hicks3, Nicholas Carlini2, Yarin Gal1,4, and Robert Kirk1.
Affiliations: 1UK AI Security Institute; 2Anthropic; 3Alan Turing Institute; 4OATML, University of Oxford; 5ETH Zurich
Related content
Anthropic Economic Index report: Cadences
In our latest Economic Index report, we sample hourly for the first time to ask: When do people come to Claude? What do they produce with it? And how do they perceive AI's impact on their work?
Read moreProject Fetch: Phase two
We report results from our latest test of whether Claude can help Anthropic employees perform sophisticated robotics tasks. We found that Claude Opus 4.7, operating without human assistance, was about 20 times faster than the fastest human team at all tasks completed by participants less than a year ago.
Read moreAgentic coding and persistent returns to expertise
This report provides evidence on how Claude Code is used in practice, based on a privacy-preserving analysis of around 400,000 interactive sessions from around 235,000 people between October 2025 and April 2026.
Read more