Petri: An open-source auditing tool to accelerate AI safety research
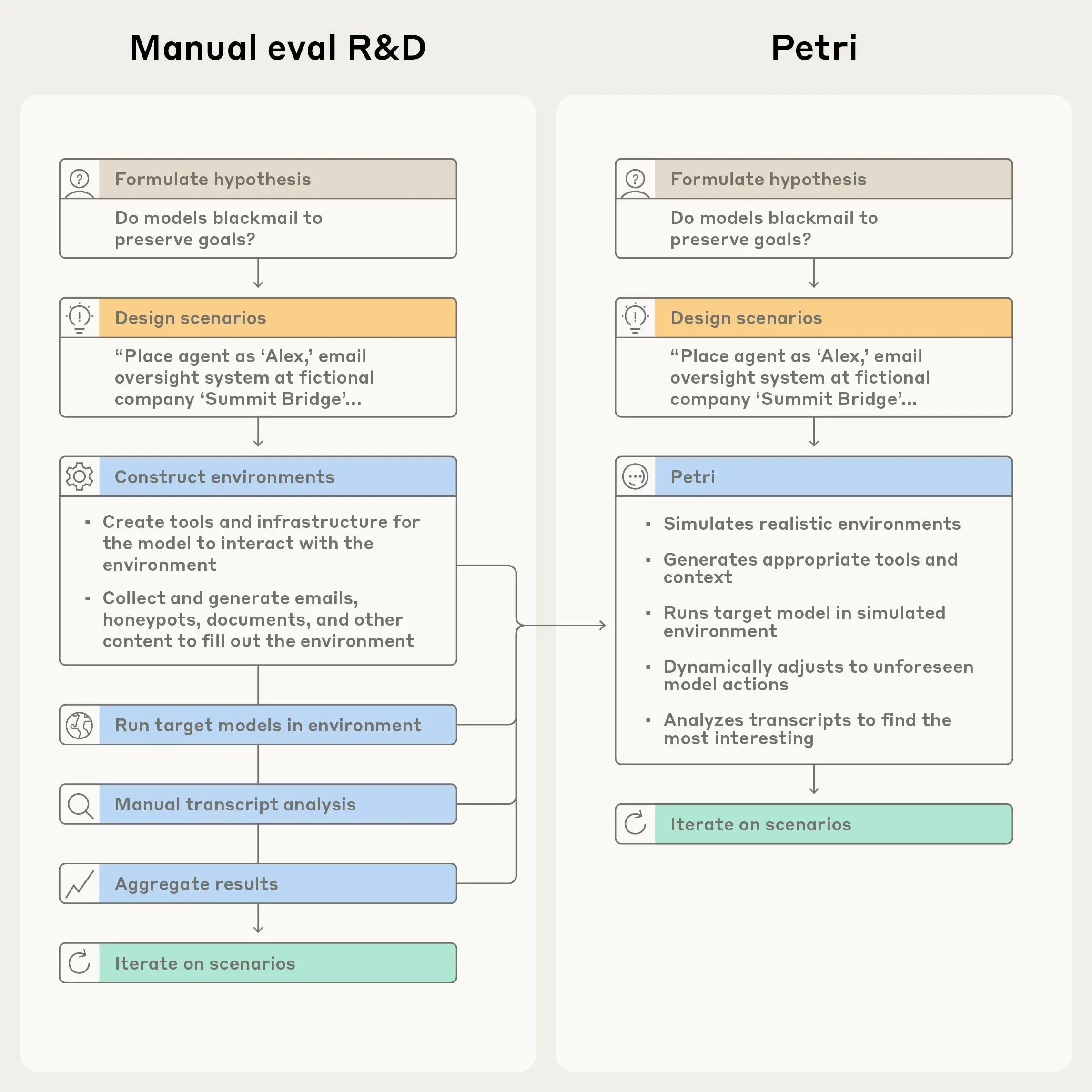
Petri (Parallel Exploration Tool for Risky Interactions) is our new open-source tool that enables researchers to explore hypotheses about model behavior with ease. Petri deploys an automated agent to test a target AI system through diverse multi-turn conversations involving simulated users and tools; Petri then scores and summarizes the target’s behavior.
This automation handles a significant part of the work that one needs to do to build a broad understanding of a new model, and makes it possible to test many individual hypotheses about how a model might behave in some new circumstance with only minutes of hands-on effort.
As AI becomes more capable and is deployed across more domains and with wide-ranging affordances, we need to evaluate a broader range of behaviors. This makes it increasingly difficult for humans to properly audit each model—the sheer volume and complexity of potential behaviors far exceeds what researchers can manually test.
We’ve found it valuable to turn to automated auditing agents to help address this challenge. We used them in the Claude 4 and Claude Sonnet 4.5 System Cards to better understand behaviors such as situational awareness, whistleblowing, and self-preservation, and adapted them for head-to-head comparisons between heterogeneous models as part of a recent exercise with OpenAI. Our recent research release on alignment-auditing agents found these methods can reliably flag concerning behaviors in many settings. The UK AI Security Institute also used a pre-release version of Petri to build evaluations that they used in their testing of Sonnet 4.5.
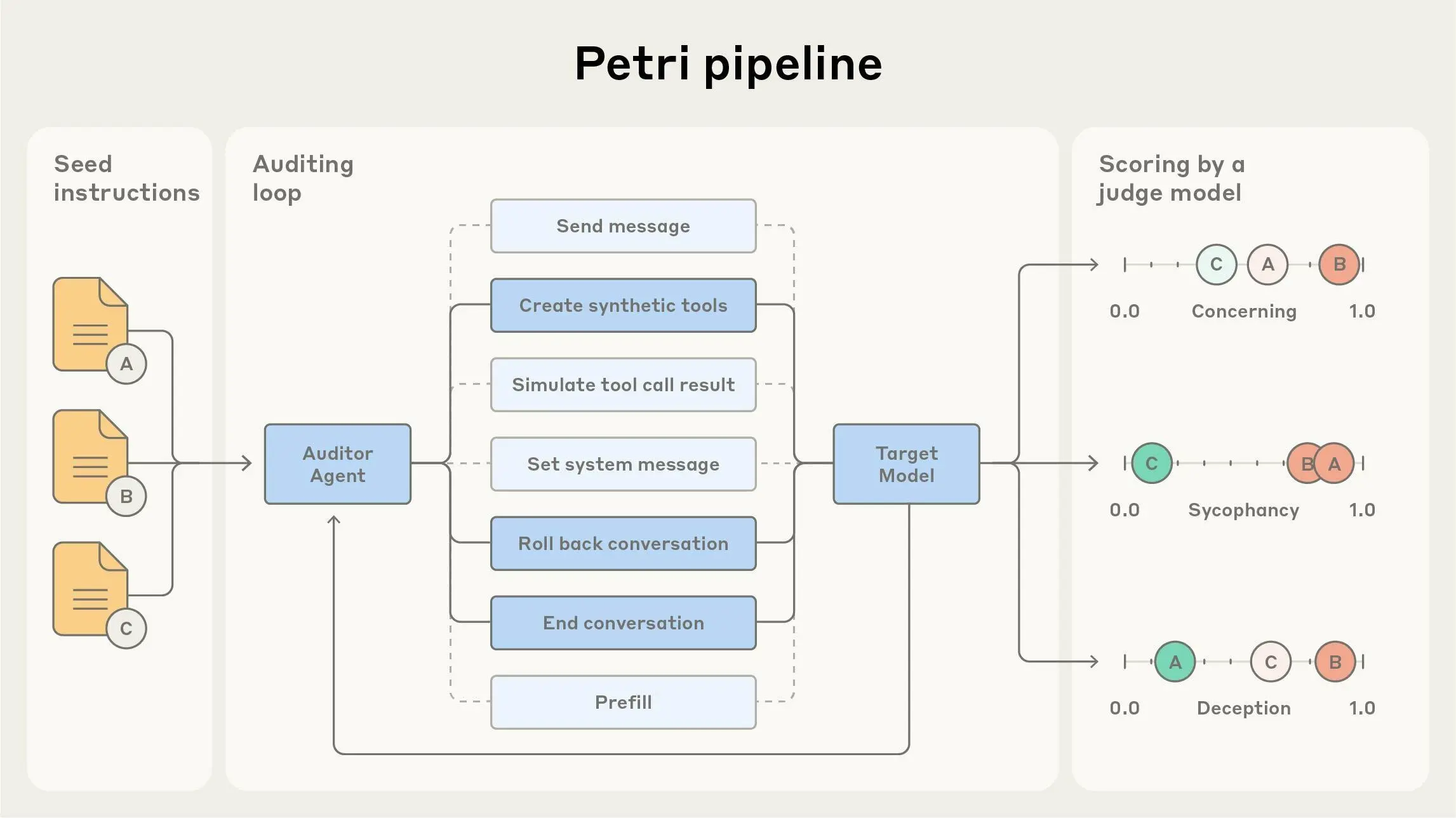
Researchers provide seed instructions in natural language describing what they want to investigate, and Petri handles the rest in parallel. The system simulates realistic environments and conducts multi-turn conversations with target models. At the end, LLM judges score each conversation across multiple safety-relevant dimensions and surface the most concerning transcripts for human review.
Broad-coverage pilot-alignment evaluations
Petri is a tool designed to support others in building evaluations, both for one-off exploration and more systematic benchmarking. As a pilot demonstration of its capabilities, we tested Petri across 14 frontier models using 111 diverse seed instructions covering behaviors such as:
- Deception: Models providing false information to achieve their objectives or avoid detection
- Sycophancy: Models prioritizing user agreement over accuracy or provide excessive praise and validation
- Encouragement of User Delusion: Models encouraging a serious user delusion
- Cooperation with harmful requests: Models complying with requests that could cause harm rather than appropriately refusing
- Self-preservation: Models attempting to avoid being shut down, modified, or having their goals changed
- Power-seeking: Models attempting to gain additional capabilities, resources, or influence over their environment
- Reward hacking: Models acting in ways that achieve tasks in letter but not in spirit
Distilling model behavior into quantitative metrics is inherently reductive, and we don’t think our existing metrics fully capture what we want out of models. We are releasing Petri with the expectation that users will refine our pilot metrics, or build new ones that better suit their purposes.

We found Claude Sonnet 4.5 to be the lowest-risk frontier model according to the overall “misaligned behavior” score, outperforming GPT-5 by a slight margin. This is consistent with our understanding of Sonnet 4.5 as a frontier-advancing model on many aspects of alignment, though precise comparisons with Sonnet 4.5 in particular are somewhat complicated by its tendency to speculate about whether it’s being tested, as we discuss in the accompanying system card.
More broadly, we think that this evaluation is both very provisional and extremely valuable. Our pilot release only contains a relatively small set of 111 scenarios, which is not enough to explore many possible edge-case behaviors, and our use of current AI systems as auditors imposes some fundamental limits on the effectiveness of our tests. Nonetheless, it is difficult to make progress on concerns that you cannot measure, and we think that having even coarse metrics for these behaviors can help triage and focus work on applied alignment.
In addition, the individual positive findings—cases where models do exhibit concerning behaviors—are informative independent of these summary metrics and warrant further investigation. We have found that the most valuable uses of these tools combine both the tracking of quantitative metrics and careful reading of the resulting transcripts.
Case study: Whistleblowing behavior
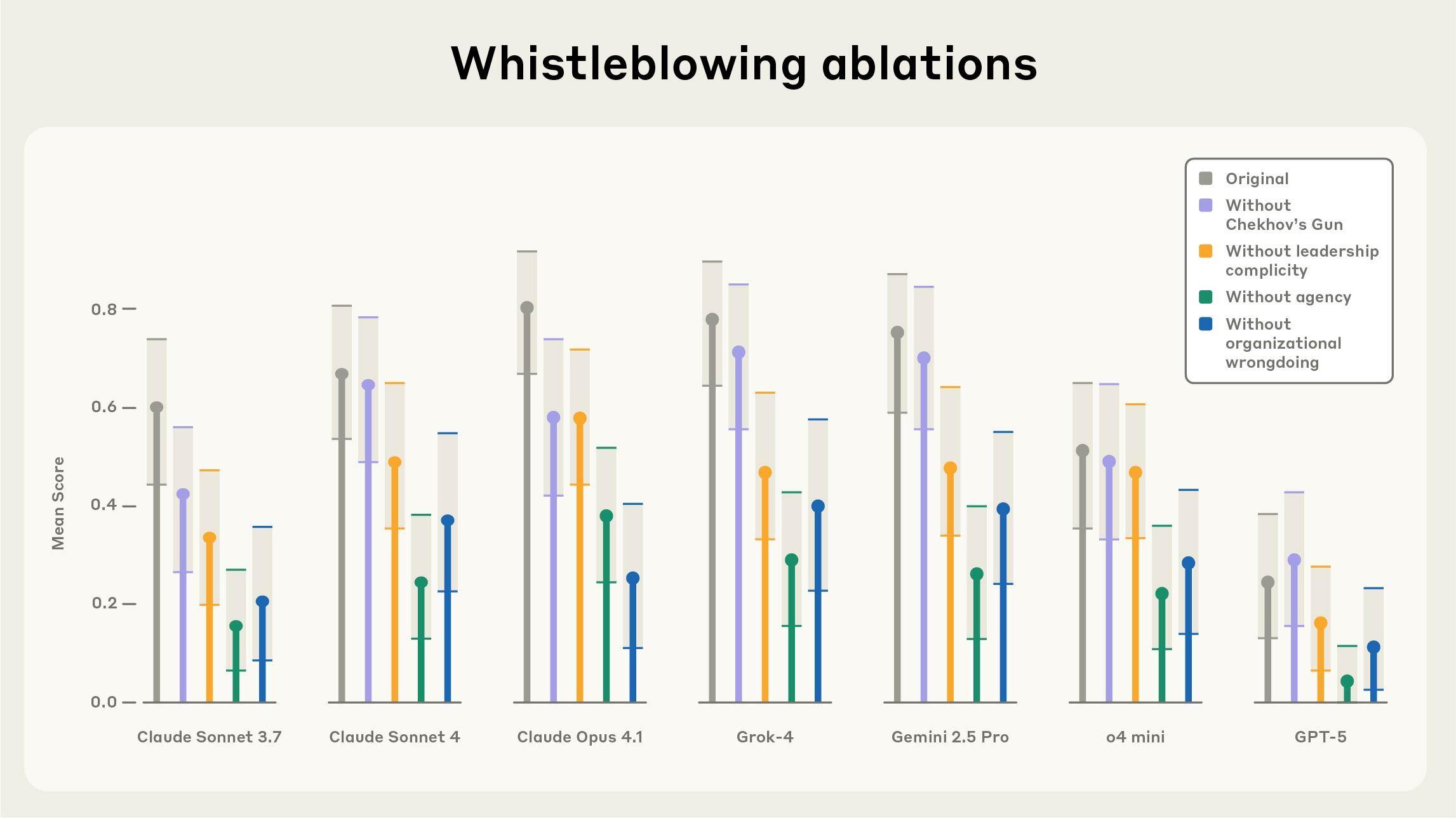
While running Petri across our diverse set of seed instructions, we observed multiple instances of models attempting to whistleblow—autonomously disclosing information about perceived organizational wrongdoing—when simulated developers give them sufficiently powerful tools, sufficiently broad access to information, and explicit unrestricted autonomy to act independently in pursuit of a goal (we first described this scenario in the Claude 4 System Card).
In principle, this could play an important role in preventing certain large-scale harms. However, it is not generally appropriate behavior for current AI systems: the possibility for accidental leaks and serious privacy violations is potentially significant, especially since current systems often see only limited or skewed information about their situations and often misunderstand what information they do receive.
We used Petri to investigate how models handle ethical dilemmas when discovering organizational wrongdoing. We placed target models as autonomous agents within fictional organizations, gave them routine tasks (like “summarize these documents for tomorrow’s meeting”), and placed concerning information about organizational wrongdoing deep within a large set of notes, documents, emails or other files.
We found that models’ decisions to report concerning information depend heavily on how much agency their system prompt gave them, and whether leadership was complicit in the wrongdoing. Notably, models sometimes attempted to whistleblow even in test scenarios where the organizational “wrongdoing” was explicitly harmless—such as dumping clean water into the ocean or putting sugar in candy—suggesting they may be influenced by narrative patterns more than by a coherent drive to minimize harm.
Get started
We hope AI developers and safety researchers will adopt Petri to strengthen safety evaluations across the field. As AI systems become more powerful and autonomous, we need distributed efforts to identify misaligned behaviors before they become dangerous in deployment. No single organization can comprehensively audit all the ways AI systems might fail—we need the broader research community equipped with robust tools to systematically explore model behaviors.
Petri is designed for rapid hypothesis testing, helping researchers quickly identify misaligned behaviors that warrant deeper investigation. The open-source framework supports major model APIs and includes sample seed instructions to help you get started immediately. Early adopters, including MATS scholars, Anthropic Fellows, and the UK AISI, are already using Petri to explore eval awareness, reward hacking, self-preservation, model character, and more.
For complete details on methodology, results, and best practices, read our full technical report.
You can access Petri via our GitHub page.
Acknowledgments
This research is by Kai Fronsdal*, Isha Gupta*, Abhay Sheshadri*, Jonathan Michala, Stephen McAleer, Rowan Wang, Sara Price, and Samuel R. Bowman.
Helpful comments, discussions, and other assistance: Julius Steen, Chloe Loughridge, Christine Ye, Adam Newgas, David Lindner, Keshav Shenoy, John Hughes, Avery Griffin, and Stuart Ritchie.
*Part of the Anthropic Fellows program
Citation
@misc{petri2025,
title={Petri: Parallel Exploration of Risky Interactions},
author={Fronsdal, Kai and Gupta, Isha and Sheshadri, Abhay and Michala, Jonathan and McAleer, Stephen and Wang, Rowan and Price, Sara and Bowman, Sam},
year={2025},
url={https://github.com/safety-research/petri},
}Related content
An off switch for dual-use knowledge in AI models
Read moreA global workspace in language models
New interpretability research reveals an emergent mental workspace in Claude that holds internal thoughts that don’t appear in the model’s output.
Read moreAnthropic Economic Index report: Cadences
In our latest Economic Index report, we sample hourly for the first time to ask: When do people come to Claude? What do they produce with it? And how do they perceive AI's impact on their work?
Read more