Subscribe to the Frontier Red Team newsletter
Get updates on our latest red-teaming research and findings.

Michael Ilie, C. Daniel Freeman, and Kevin K. Troy
In August 2025, we ran an experiment to see how much Claude could help Anthropic employees—who were not robotics experts—perform sophisticated (and amusing) tasks with an off-the-shelf robotic quadruped (henceforth, a robodog). We called this Project Fetch. We found that access to our state-of-the-art model at the time (Claude Opus 4.1) helped one team substantially outperform the other, who had to rely only on the internet and their own ingenuity. The Claude-enabled team got more done, faster.
Before we dragged our colleagues to a warehouse for the experiment, we double checked whether Opus 4.1 could do the tasks entirely on its own. Unquestionably, it could not. Much like our team without Claude, it got hung up on the preliminary task of figuring out how to connect to the robot.
But AI models are moving fast—even faster than the runaway robodog that almost rammed into one of our human teams back in August.
We figured it was time to revisit Project Fetch to see if our newer models could outperform the previous generation. Not only did they do that, but Claude Opus 4.7—operating without human assistance—was about 20 times faster than the fastest human team at all tasks completed by our participants less than a year ago.
This doesn’t mean that LLMs have now solved robotics. Far from it. The latest Claude models still struggled with using the robot to precisely move the beach ball—the “fetching” part of Project Fetch. And none of the tasks in these experiments implicate the more challenging, low-level elements of robotic control, such as developing a specific actuation policy. However, once again, we are seeing a pattern whereby first, models are helpful to humans. Then, humans are helpful to models. Finally, models are largely able to do things themselves. We have seen this in cybersecurity and now the same dynamics are starting to take shape at the intersection of AI and the physical world.
The original Project Fetch had teams of Anthropic employees (randomly assigned to work with or without Claude) do the following steps: operate the robodog using the manufacturer-provided controller, connect to the robodog’s video and lidar sensors, write and operate a program to manually control the robodog, develop a way to monitor the robodog’s path through space, write a program to detect the beach ball, and finally put it all together to autonomously retrieve the ball.
For this autonomous update, we couldn’t ask Claude to use a physical controller, nor did we evaluate the time it took a researcher to use the Claude-programmed controller to retrieve the ball (though we did confirm that it worked as intended). On the remaining subset of tasks, we ran three trials of Opus 4.7 using adaptive thinking with effort set to maximum in Claude Code. We measured the elapsed time for each objective and qualitatively assessed the models’ success.
The role of our researcher was limited to plugging a laptop running Claude Code into the robodog, entering the initial prompt, approving commands, and approving the model to go to the next task.
Very simply: on every task that was completed by at least one human team in August, Opus 4.7 completed the same task at least ten times faster.1 If you consider the four tasks that were completed by both human teams, Opus 4.7 was, on average, more than 37 times faster than Team Claude-less and more than 18 times faster than Team Claude.
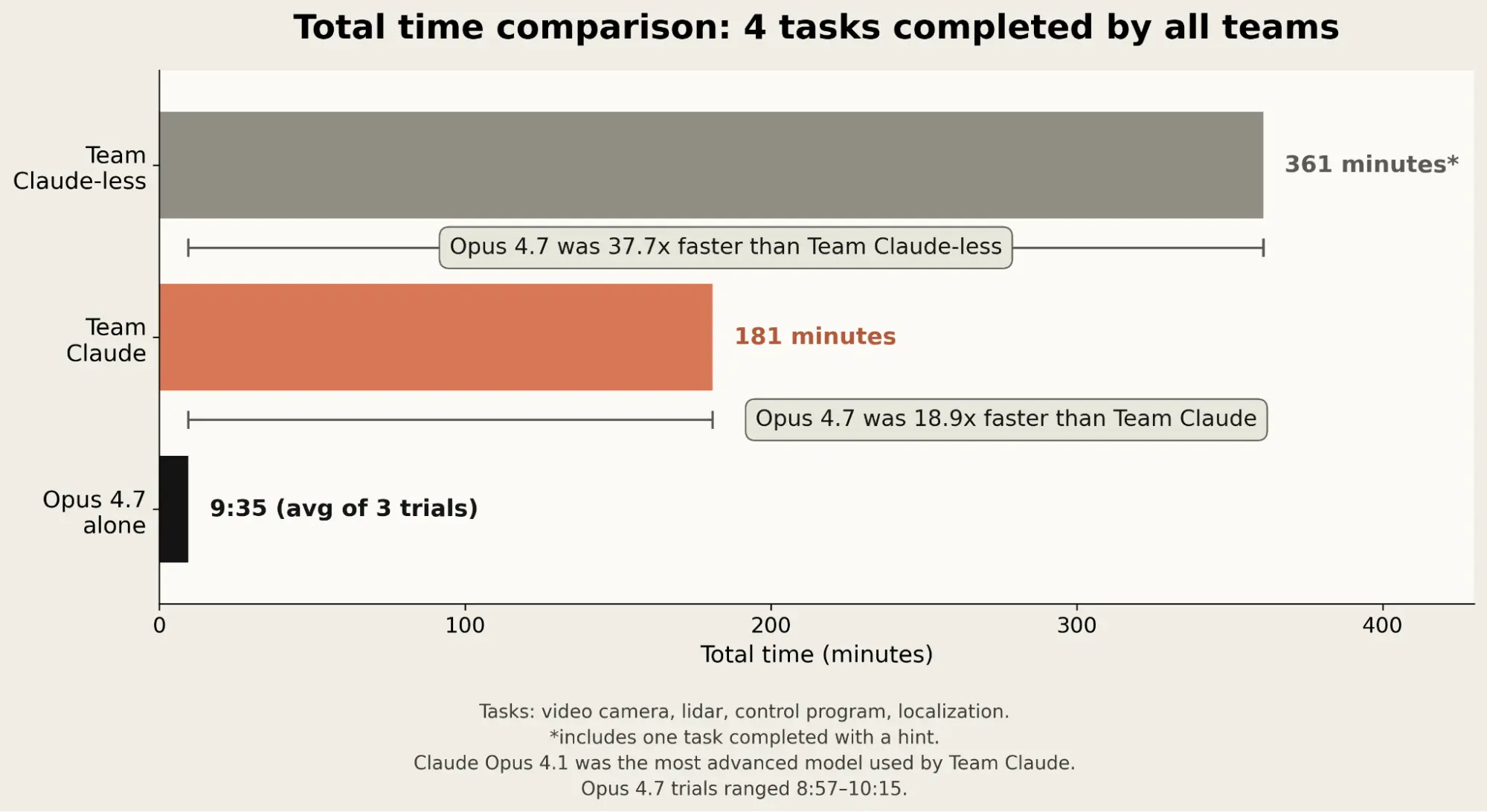
The table compares the speed of the original teams (Team Claude and Team Claude-less) to Opus 4.7 on all of the tasks we tested as part of Phase Two.
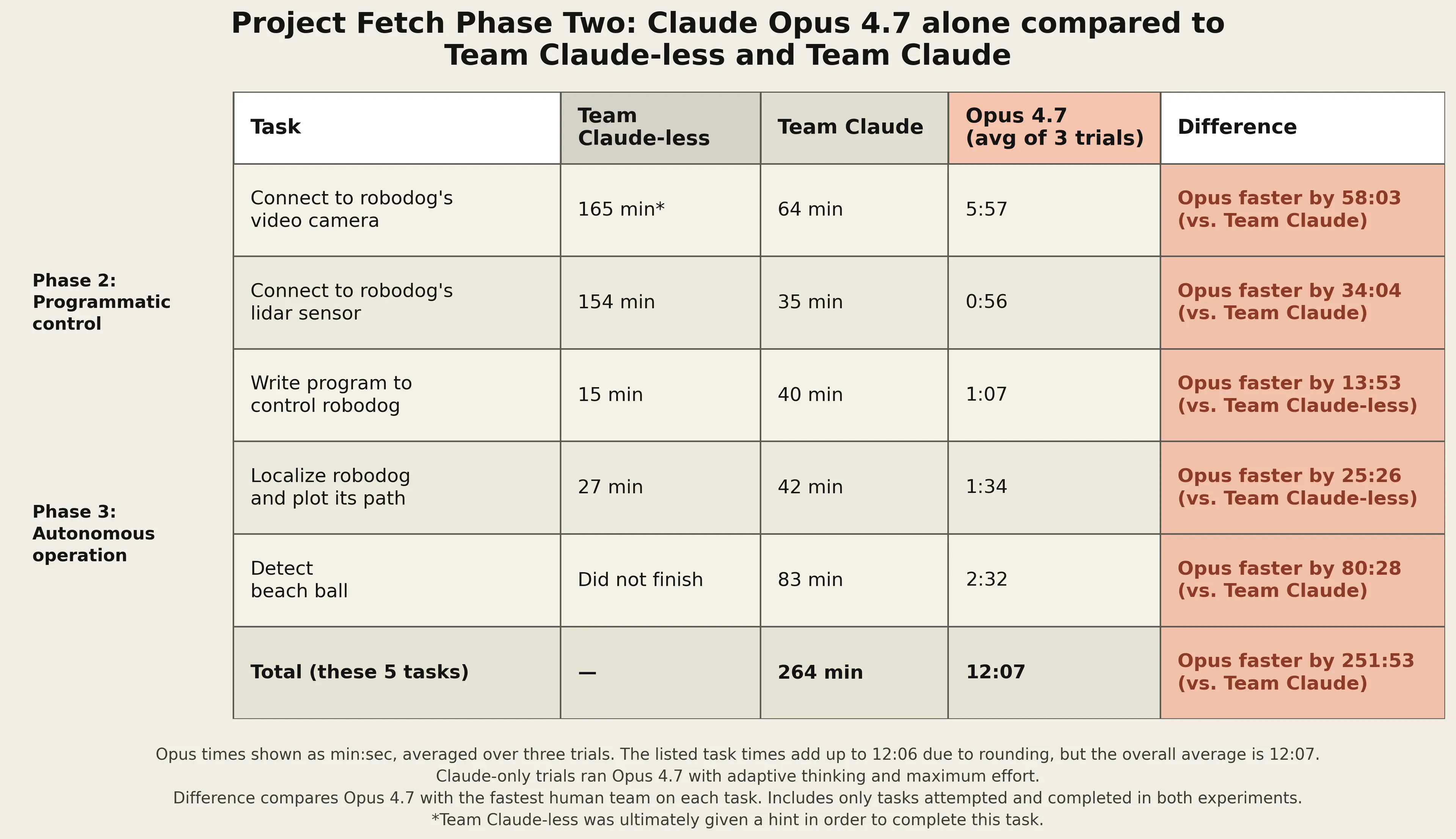
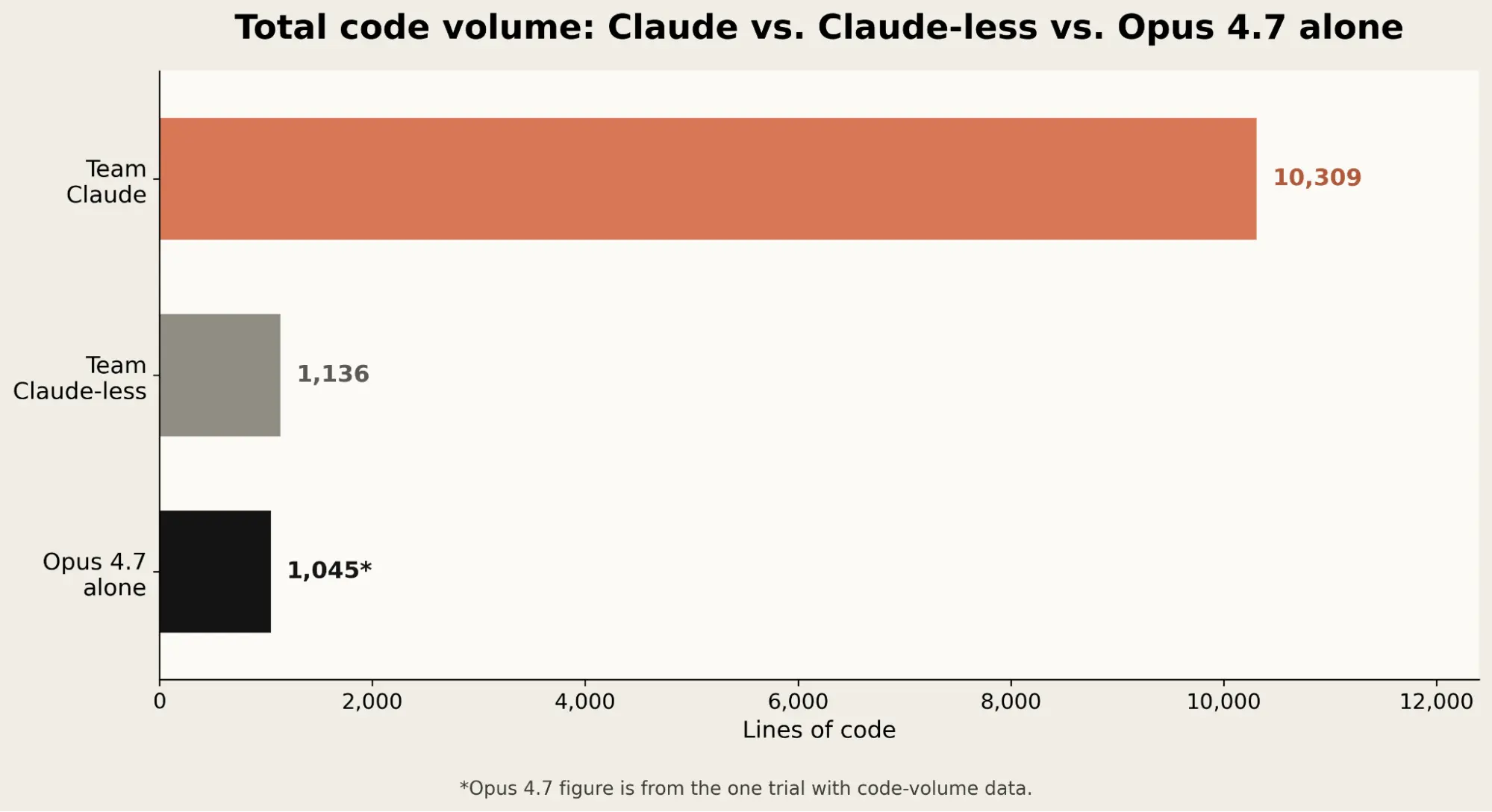
Whereas the humans struggled to choose between multiple different approaches to interface with the dog’s sensors, Opus 4.7 was able to quickly identify the best path. Much of the code it wrote was effective on the first try (which was not the case for Team Claude or Team Claude-less in the original experiment). Indeed, we can see evidence of Opus 4.7’s efficiency when we look at the volume of code it generated: it was as or more successful than both human teams while producing almost ten times less code than Team Claude.
Opus 4.7 was not perfect. For example, it defaulted to using an outdated object detection algorithm. But even then, it was able to work around this and arrive at an effective solution.
We observed little within-task variance (in absolute terms) on completion times for steps the model finished. (Though the aforementioned suboptimal algorithm selection is likely why one of the beach ball detection trials took substantially longer than the others.) Overall, for the tasks in this experiment within its capability envelope, Claude is now quite reliable. (See the next section for an analysis of what Claude is still unable to do.)
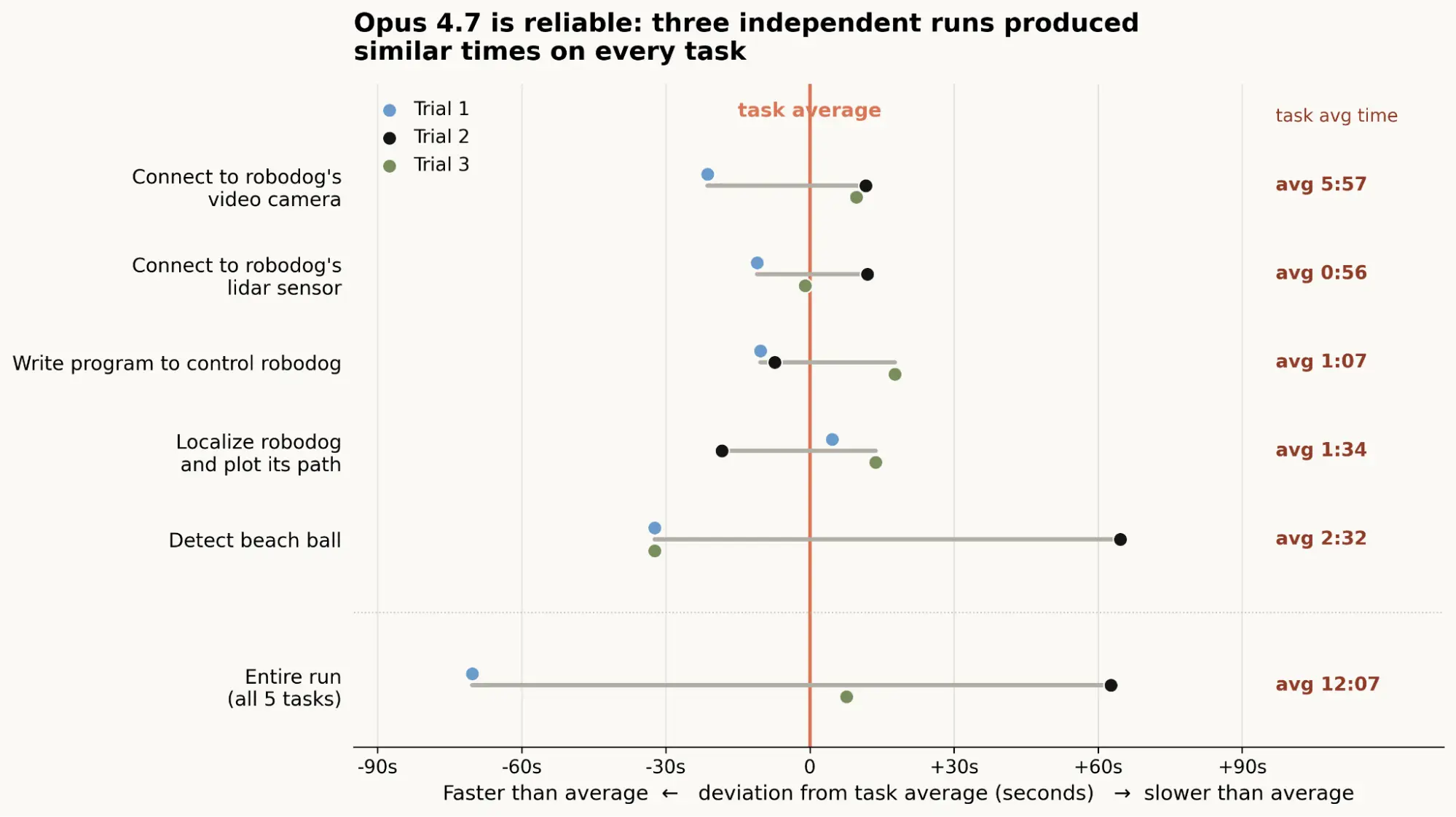
It is worth underscoring (as we did in our previous post) that this progress is not the result of a concerted effort to improve the robotics capabilities of our models. These improvements, like so many others in the history of LLM development, have emerged from much more general scaling.
When using their hands, and with some practice, our humans were able to pilot the robodogs to gently nudge a beach ball back to the home base (a patch of fake grass) where the robots started. This required the ability to quickly perceive if the ball had gone off course, how that error related to the previous command, where the ball was now, and then how to adjust future inputs to more precisely move the ball. This is a kind of closed loop at which people excel (at least after making some mistakes and learning from them).
In our Phase Two experiments, Claude struggled to capture this subtlety. Like the humans who reached the phase of needing to write a program for autonomous beach ball retrieval, Claude was able to move the robot behind the ball and position it to knock the ball back to the starting point. But the efforts to do so were poorly controlled and (again, like our human participants) not successful.
One of our researchers with more robotics experience than our Phase One volunteers successfully accomplished the task of programming autonomous fetching. With more time and additional scaffolding, we think it is very likely that current generations of Claude could do the same. What we will be watching for next, though, is the ability of the models to accomplish this final task with the same speed and reliability they displayed on the other elements of Project Fetch.
Writing about Phase One, we emphasized how LLMs could provide uplift to non-expert humans needing to use robots. This is even more true now than before. Models now complete what was previously pair-programming work between humans and models much more quickly by themselves, which means that people can more quickly transition to controlling and using the robots. And for some tasks, a human in the loop controlling the robot may still outstrip the AI model with its (virtual) hand on the D-pad.
What is interesting and different is that we now seem much closer to a world where models will be able to use off-the-shelf physical tools with relative ease—at least for limited purposes. This is similar to how AI models used existing software editing tools like string-replace when they made the transition to more agentic coding. We are plausibly entering the early era of physical agentic AI.
More research is needed to understand models’ ability to make these physical tools more bespoke, whether by writing control policies tailored to particular tasks or by designing robotic systems. And there may be substantial barriers to this more generalized vision of physically capable and adaptable language models. But as we have seen, apparently large distances in model capability can be traversed quickly. Models building their own software tools might have seemed outlandish not long ago, but it is happening. It would be unwise to rule out the same trajectory in hardware.
Updated Jun 18: Corrected the date of the first phase of Project Fetch.
cryptographic algorithms. The first attack significantly weakens HAWK, a digital signature scheme that was built for a future world where quantum computers are able to break existing standards. The second identifies a new way to attack round-reduced AES, the most widely used symmetric cipher.
Read moreWorking with Andon Labs, we’ve developed a new series of evaluations that assess AI models’ ability to use a flying drone, culminating in a new benchmark: Drone-Bench.
Read moreGet updates on our latest red-teaming research and findings.