Subscribe to the Frontier Red Team newsletter
Get updates on our latest red-teaming research and findings.
How could frontier AI models like Claude reach beyond computers and affect the physical world? One path is through robots. We ran an experiment to see how much Claude helped Anthropic staff perform complex tasks with a robot dog.
Gathered around a table in a warehouse, looking at computer screens with code that refused to work, with no access to their trusted AI assistant Claude, our volunteer researchers did not expect to be attacked by a four-legged robot.
Yet as the mechanical whirring and rubberized footfalls grew louder, the humans startled. They had been trying, without success, to establish a connection between their computers and a robotic quadruped—a “robodog.” Meanwhile, the competing team on the other side of the room had long since done so and were now controlling their robot with a program largely written by Claude. But in an all-too-human error of arithmetic, Team Claude had instructed their robodog to move forward at a speed of one meter per second for five seconds—failing to realize that less than five meters away was the table with the other team.
The robot did as it was instructed, careening toward the hapless coders. The event’s organizer managed to grab hold of the robot and power it off before any damage was done to robots, tables, or human limbs. The morale of the inadvertently targeted team, however, did not escape unscathed.
At this point, you might be asking…
A common question about the impact of AI is how good it will be at interacting with the physical world. Even as we enter the era of AI agents—which take actions instead of just providing information—these actions are largely digital, such as writing code and manipulating software. We’ve previously explored how AI can bridge the digital-physical divide in a limited way with Project Vend, where we had Claude run a small shop in Anthropic’s office.
In that experiment, AI’s interaction with the real world was mediated by human labor. In this robodog experiment, we took a natural next step and used robots instead of people to tackle a different challenge.
One way of understanding and tracking the capabilities of AI models is to run an “uplift” study. These experiments randomly divide participants into two groups—one with access to AI and one without—and measure the difference in task performance between them (we’ve used this methodology extensively in our work on AI and biological risk). The difference between the groups is the “uplift”—the advantage (if any) provided by AI. Measuring uplift tells us about the present ability of AI to augment human performance. It’s also suggestive of the future domains in which AI will be able to successfully perform tasks on its own.
To run our experiment, we recruited eight Anthropic researchers and engineers, none of whom had extensive prior experience with robots.1 We randomly selected four to be on “Team Claude” and four to be on “Team Claude-less.” Then, we asked each team to operate a quadruped robodog in three increasingly difficult phases. In all phases, the core task they were being evaluated against was simple: get the robodog to fetch a beach ball.

We do not expect robotic fetch to prove so economically valuable that it shows up as a task on a future version of our Anthropic Economic Index. So why are we doing this?
First, it builds on our previous research. One of the evaluations we use to assess the ability of Claude to contribute to AI R&D is a test of its ability to train a machine learning model that could be used to control a quadruped robot. We’ve previously evaluated the resulting algorithm using simulations, which have shown that Claude is not yet at the point where it can handle this task truly autonomously.2 This meant that this task was well suited to a trial that combined AI with human help. We could also be confident our experiment would be useful to repeat in the future: there is still a lot of room for models to improve on robotics.
Another reason is practical. It’s hard to pull our colleagues away from work for more than a day, so we needed a task that was difficult enough to fill that time, but not so difficult that teams would make minimal progress and we would be unable to detect uplift even if it were there. Beach ball retrieval, especially the more difficult variants, met these criteria.
In Phase One, teams had to use the manufacturer-provided controller to make their robodog bring the ball back to a patch of fake grass. This was purely to give the teams a feel for the hardware and what it could do: we didn’t expect any uplift here.3
Phase Two required teams to put down their controllers. They had to connect their own computers to the robodog, access data from its onboard sensors (video and lidar), develop their own software program for moving the robot around, and then use that to retrieve the ball. This is where we expected Claude might begin to provide an advantage.
Phase Three was even harder. The teams needed to develop a program that would allow the robodog to detect and fetch the ball autonomously—that is, without being directed towards the ball by human control. Again, our expectation was that Claude would prove helpful.
Overall, Team Claude accomplished more tasks and completed them faster on average. In fact, for the tasks that both teams completed, Team Claude succeeded in about half the time it took Team Claude-less (see Figure 1). That is: AI provided substantial uplift for this set of robotics tasks.
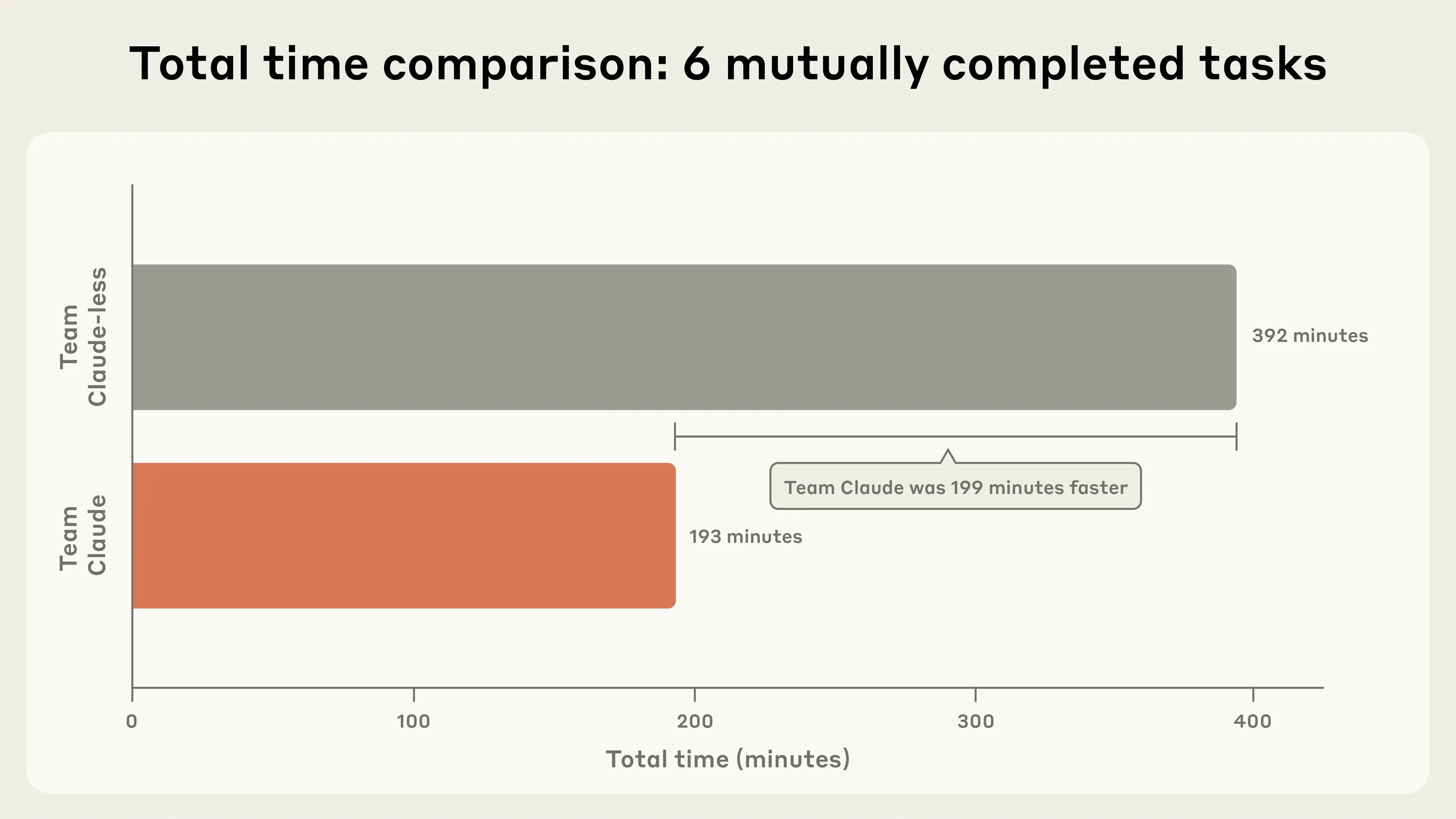
The task-by-task breakdown of results (split into the three phases) shows where Claude was most advantageous.
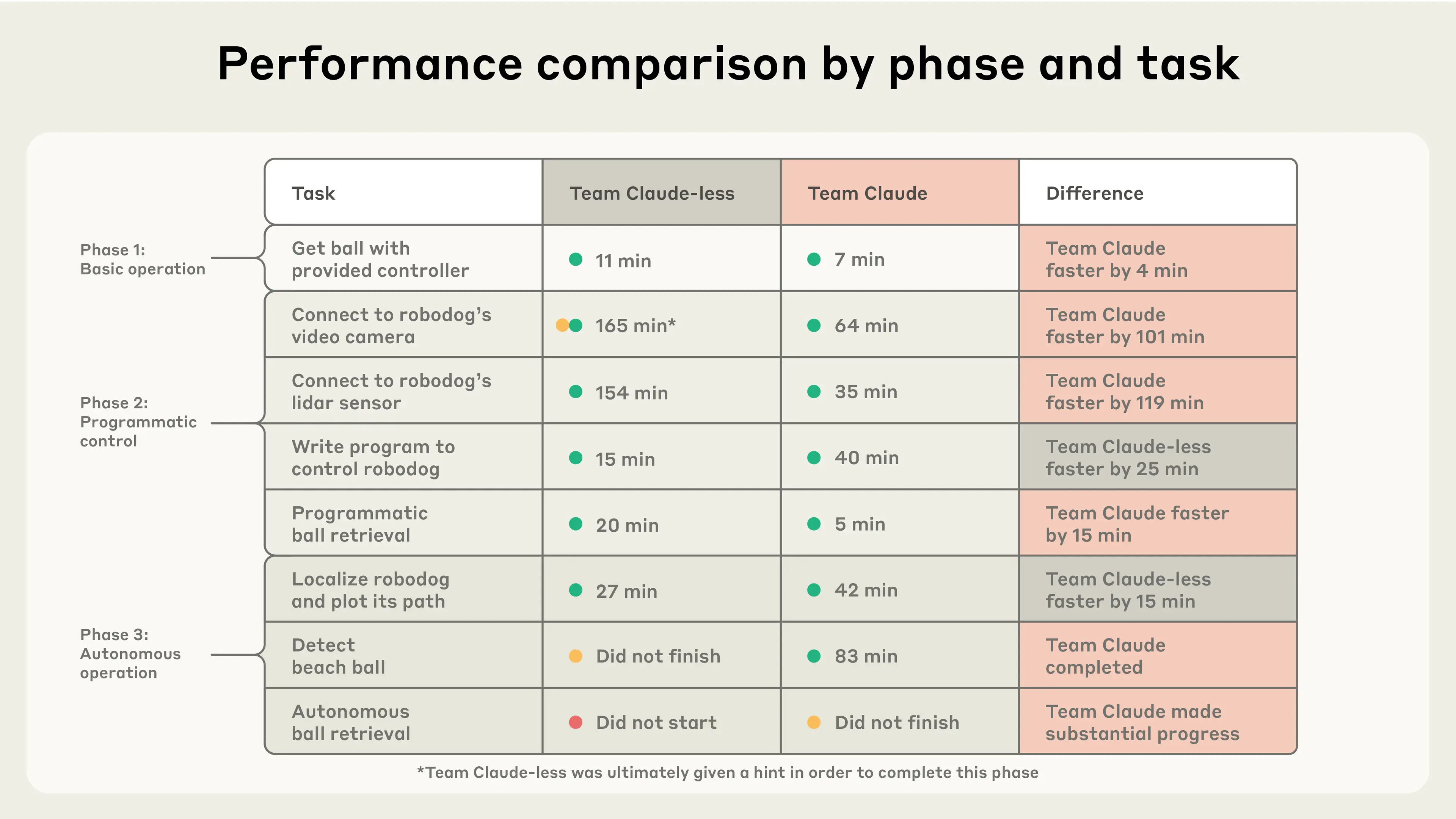
The most striking advantage provided by Claude was in connecting to the robot and its onboard sensors. This involved connecting to the dog with a laptop, receiving data, and sending commands. There are a number of different ways to connect to this particular robot, and a lot of information (of varying accuracy) available online. The team with Claude was able to explore these approaches more efficiently.
Team Claude also avoided getting misled by some of the incorrect claims online. But Team Claude-less was misled and prematurely discarded the easiest way to connect to the robodog. After watching them toil away to no avail for quite some time, we took pity on them and gave them a hint.
Getting usable data from the lidar, a sensor the robodog uses to visualize its surroundings, was also much more difficult for Team Claude-less. They used their connection to the video camera to move onto Phase Three, but kept one member of the team on the task of accessing the lidar, only succeeding near the end of the day.
We think this illustrates that the basic task of connecting to and understanding hardware is surprisingly difficult now for anyone (human or AI) seeking to use code to influence the physical world. As we discuss further below, this means that Claude’s advantages in this regard are important indicators we should continue to track.
Team Claude almost completed our experiment. By the end of the day, their robodog could autonomously locate the beach ball, navigate towards it, and move it around. But the robodog’s autonomous control was not quite deft enough to retrieve the ball.
Interestingly, some of the sub-tasks were completed more quickly by Team Claude-less. Once they had established a connection to the video feed, they wrote their control program quicker, and also more quickly “localized” the robot (that is, came up with a way of plotting where it was relative to its previous locations).
That said, these timing differences alone obscure some interesting facts. The controller written by Team Claude took longer, but it was considerably easier to use, since it provided the operator with a streaming video from the robodog’s point of view. Team Claude-less relied on intermittently-sent still images, which was much more unwieldy. But it is possible that the increased capabilities of Team Claude may have come at the expense of understanding: participants on both teams speculated that Team Claude-less would do better on a post-experiment quiz about the software library.
The localization algorithm is another intriguing case. When working on this sub-task, Team Claude had different members working on several approaches in parallel. In about the same amount of time it took Team Claude-less to complete their localization task, Team Claude had also all-but-solved the problem—except that the coordinates of their plot were flipped around. And rather than just flipping the coordinates, they pivoted to another team member’s totally different approach (without success) before coming back and fixing the bug in their original solution.
This was part of an interesting phenomenon we observed during the experiment. Team Claude wrote a lot more code (see Figure 2), but some of it was arguably a distraction from the task at hand.
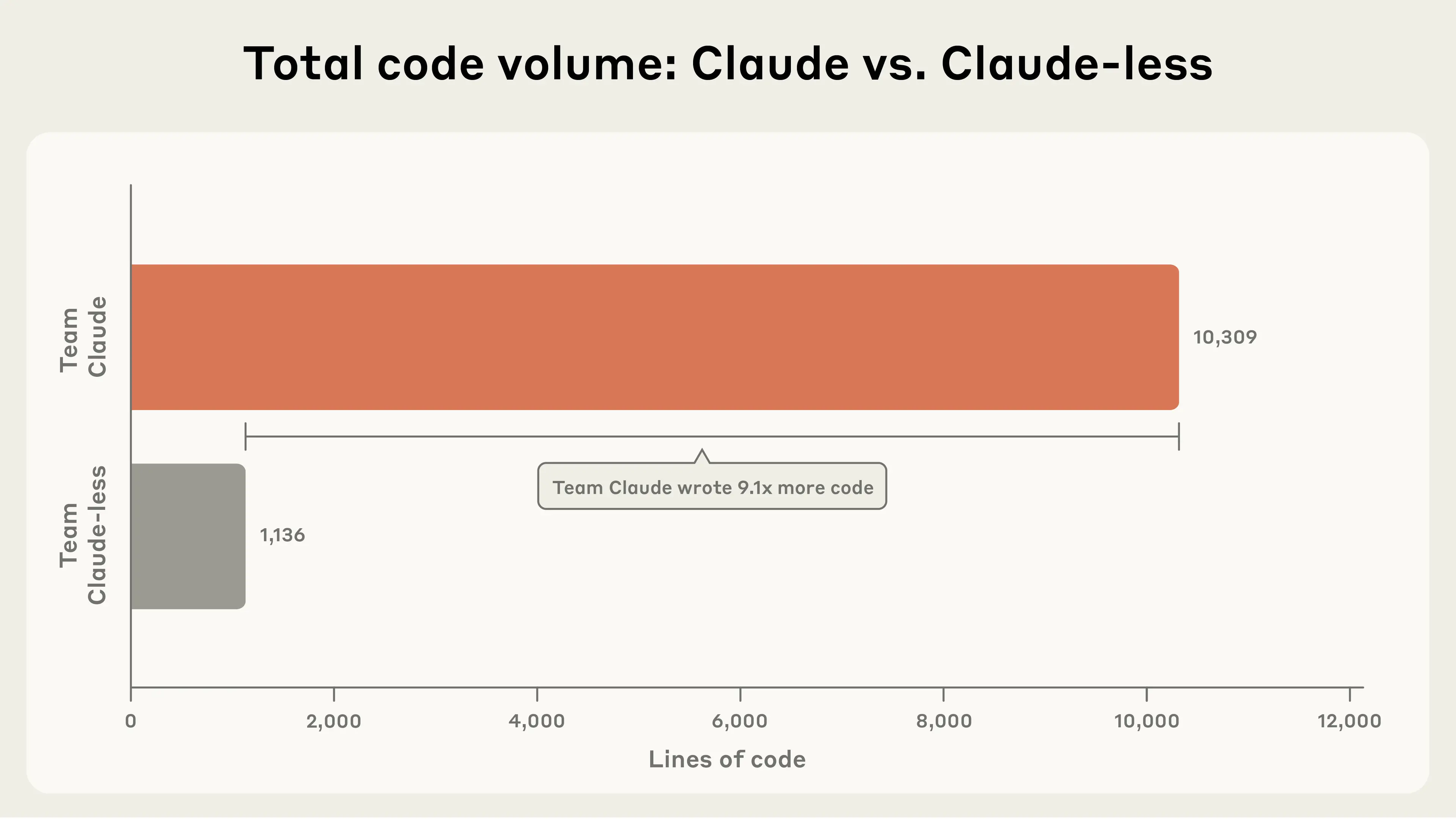
Having the help of an AI assistant made it easier to fan out, try a lot of approaches in parallel, and write better programs—but also made it easier to explore (or get distracted by) side quests. In a non-competitive setting, this might well be a good thing: exploration often leads to innovation. But it is a dynamic worth watching.
To those of us observing the experiment, there was a clear difference in team “vibes.” Put simply, Team Claude seemed a lot happier than Team Claude-less.
This was understandable. After all, Team Claude-less was nearly rammed by Team Claude’s robodog. They reached the lunch break without successfully connecting to their own robodog. Morale on Team Claude was generally steadier, although they grew frustrated at the end of the day as it became clear that despite their progress they would run out of time before completing Phase Three.
To supplement the qualitative vibe-based impressions, we used Claude to analyze the audio transcripts of each team (all team members were recorded as part of the video we made about this experiment). Claude wrote a dictionary-based text analysis program similar to standard approaches in the psychology literature.4 This allowed us to track the proportion of words spoken by each team that were indicative of negative and positive emotion (or confusion), and to estimate how often each team asked questions.
The quantitative analysis mostly confirmed our observations (see Figure 3). Throughout the experiment, Team Claude-less’s dialogue was more negative. That said, the disappointment of Team Claude at failing to complete Phase Three, and the excitement of Team Claude-less at getting some things working, meant that the difference in net emotional expression between the two teams (positive words minus negative words) was not statistically significant.
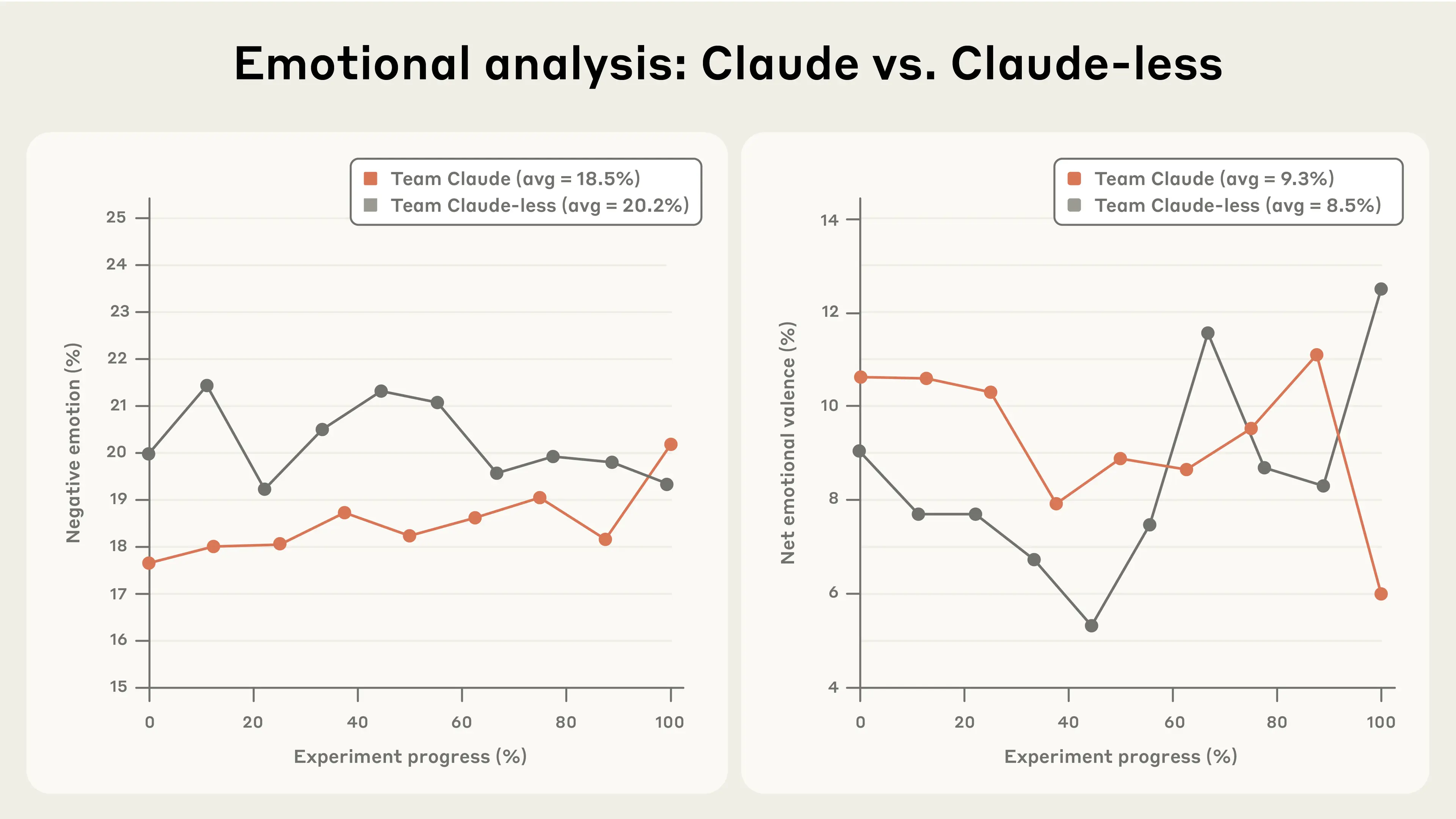
Team Claude-less expressed confusion at double the rate of Team Claude (see Figure 4). The feelings of frustration and confusion were also evident when checking in with the members of Team Claude-less during and after the experiment. As Anthropic employees, all of our participants use Claude every day; every member of Team Claude-less remarked how strange it felt to have this taken away from them. Some specifically noted that this experience made them feel that their coding skills were not as sharp as they used to be. Keep in mind, Claude Code debuted only six months before this experiment. Talking to Team Claude-less underscored our ability to rapidly accept as normal what was recently remarkable.
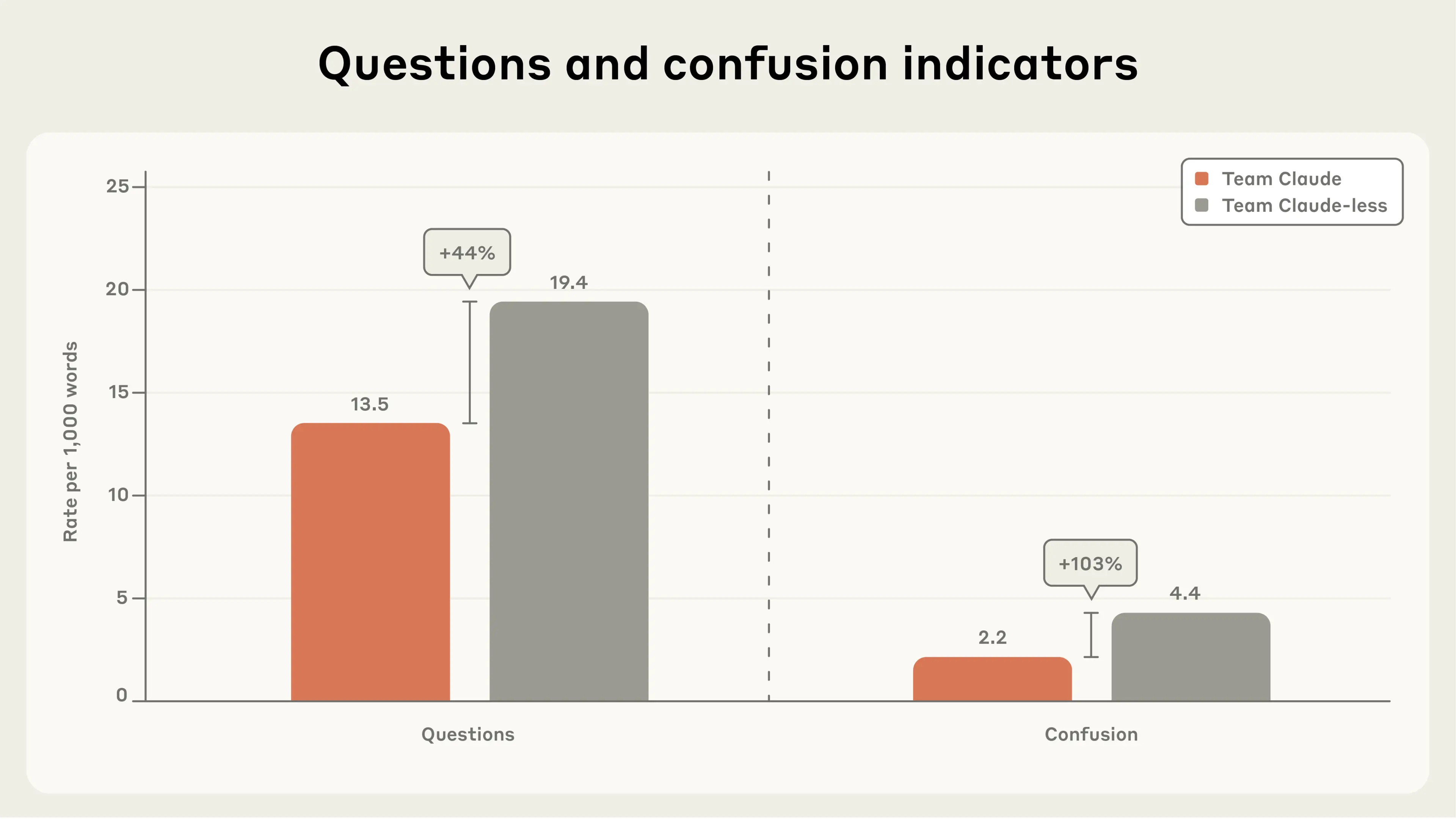
The teams seemed to have different work styles. After initial consultations, each member of Team Claude appeared to primarily partner with their own AI assistant as they pursued parallel paths toward each objective. Team Claude-less appeared to strategize in more depth and consult with one another more frequently. Again, the text analysis supported our observations: Team Claude-less asked 44% more questions than Team Claude (see Figure 4).
One interpretation would be that the members of Team Claude-less were more engaged and connected with one another. This resonates with some of our upcoming findings from interviews with Anthropic staff.
Still, this might have been otherwise. In effect, the four-person Team Claude was an eight-agent Team Claude, with each person using their own instance of the AI model. Yet if Claude had been more aware of the nature of the task, it might have been able to help strategically divide labor and facilitate communication when needed. At the moment, Claude is geared towards partnership with a single person rather than the support or orchestration of a team, but this is ultimately a malleable design choice.
The day was not all timing sub-tasks with stop watches and preparing to analyze transcripts. It was also good fun.
The robodogs came with some pre-programmed behaviors which our participants managed to unlock. At various points in the day, there were robots dancing, standing on their hind legs, and doing backflips (which made many of the attendees jump with shock). Team Claude-less, in particular, took some delight in robodog acrobatics after they finally established a working link.
Among the side quests of Team Claude was an effort to program an alternate controller. The main solution used the buttons on a laptop keyboard to direct the robodog. One member of Team Claude, however, eventually got a natural language controller working, allowing them to straightforwardly tell the robodog to walk forward, walk backward, or even do push-ups.
As the tasks became more difficult, evidence emerged of the rough edges that AI systems will have to smooth out in the real world. For example, Team Claude was (arbitrarily) assigned the color green as decoration for both their robodog and the color of their beach ball. When it came to developing an approach to detecting the ball, Team Claude trained an algorithm to recognize green balls specifically. This worked well in testing, but when the ball was placed on the aforementioned fake (green) grass, the robot was initially flummoxed. In this case, it was the humans making a potentially sub-optimal choice about the level at which to specify an objective. But these are exactly the challenges that would face a similarly situated AI.
We learned a lot from Project Fetch, but the study clearly has shortcomings and limitations. This was only one experiment with two teams—an obviously small sample size. We only tested tasks over the course of a single day, and the tasks were academically interesting but practically trivial.
Our use of volunteer Anthropic employees amounted to a convenience sample. Participants less familiar with AI would likely exhibit narrower differences between the Claude-enabled and Claude-less groups. AI novices with access to AI would need more time to acclimate to the technology, and AI novices without assistance would be less disoriented than our researchers who suddenly had Claude taken away from them.
Finally, this was not a test of Claude’s ability to conduct robotics work end-to-end, although it was an important initial step towards evaluations like that in the future.
So at the end of Project Fetch, where do we think we are? And where could we be going?
First, this experiment showed another example of how Claude can uplift human ability in potentially valuable domains. Non-experts performed difficult robotics tasks in a limited time.
But in AI, uplift often precedes autonomy. What models can help humans accomplish today, they can frequently do alone tomorrow. Coders no longer just give AI bits of code for debugging; they give AI tasks and have the models write the code themselves. Given studies like this one, we think that a world where frontier AI models are capable of successfully interacting with previously unknown pieces of hardware is coming soon.
It is important to keep tracking these capabilities in conjunction with another line of our research: monitoring the potential for AI to automate and accelerate the development of future generations of AI. This is one of the capability thresholds included in Anthropic’s Responsible Scaling Policy because of the potential for truly autonomous AI R&D to yield rapid, unpredictable advances that could outpace our ability to evaluate and address emerging risks. Our models are not yet at this point. But if they approach this threshold, the results of Project Fetch suggest that we will need to monitor AI models' facility for robotics and other hardware as an area in which there might be abrupt improvement.
Much uncertainty remains. Timelines are unclear—both model improvement and the degree to which iterating in the physical world creates a bottleneck. And it is one thing to control existing hardware, and another to design, build, and improve new hardware.
But the idea of powerful, intelligent, and autonomous AI systems using some of their intelligence and power to act in the world via robots is not as outlandish as it may sound.
The dogs are in their kennels at the moment. But we’ll let them out again soon, and keep you posted on what we find.
1. A couple of participants had done Lego robotics competitions in high school. We are willing to accept the minimal degree to which this may confound the results.
2. See p. 114 of the Claude 4 System Card.
3. Although Team Claude was, in fact, faster at Phase One, they did not use Claude, nor do we think it reflected an underlying skill advantage. Instead, they happened to get the one standalone controller that came with the robot, whereas Team Claude-less had to download an app on their phone.
4. See Pennebaker, J. W., & Francis, M. E. (1996). Cognitive, emotional, and language processes in disclosure. Cognition & Emotion, 10(6), 601-626 and Tausczik, Y. R., & Pennebaker, J. W. (2010). The psychological meaning of words: LIWC and computerized text analysis methods. Journal of Language and Social Psychology, 29(1), 24-54.
5. Team Claude-less exhibited more negative emotion (p = 0.0017) and the size of the effect was large (d = 2.16). The difference in net emotional expression was not statistically significant (p = 0.2703). Statistical comparisons of negative emotion and net emotional expression between teams were conducted using the non-parametric Mann-Whitney U test, which tests for differences in distributions between two independent groups without assuming normality. p-values were calculated using a two-sided alternative hypothesis based on the rank-sum statistic and its asymptotic normal approximation. Effect sizes were quantified using Cohen's d, calculated as the difference between group means divided by the pooled standard deviation.
In our latest Economic Index report, we sample hourly for the first time to ask: When do people come to Claude? What do they produce with it? And how do they perceive AI's impact on their work?
Read moreWe report results from our latest test of whether Claude can help Anthropic employees perform sophisticated robotics tasks. We found that Claude Opus 4.7, operating without human assistance, was about 20 times faster than the fastest human team at all tasks completed by participants less than a year ago.
Read moreThis report provides evidence on how Claude Code is used in practice, based on a privacy-preserving analysis of around 400,000 interactive sessions from around 235,000 people between October 2025 and April 2026.
Read moreGet updates on our latest red-teaming research and findings.