Automated Alignment Researchers: Using large language models to scale scalable oversight
Large language models’ ever-accelerating rate of improvement raises two particularly important questions for alignment research.
One is how alignment can keep up. Frontier AI models are now contributing to the development of their successors. But can they provide the same kind of uplift for alignment researchers? Could our language models be used to help align themselves?
A second question is what we’ll do once models become smarter than us. Aligning smarter-than-human AI models is a research area known as “scalable oversight”. Scalable oversight has largely been discussed in theoretical, rather than practical, terms—but at AI’s current pace of improvement, that might not be the case for much longer. For instance, models are already generating vast amounts of code. If their skills progress to the point where they’re generating millions of lines of incredibly complicated code that we can’t parse ourselves, it could become very difficult to tell whether they’re acting in the ways we intend.
In a new Anthropic Fellows study, we pursue both of these questions.
Our new study focuses on a problem known as “weak-to-strong supervision”, a problem that mirrors the one of overseeing smarter-than-human AI models. We start with a relatively strong “base” model—that is, a potentially-capable model that hasn’t yet received fine-tuning to provide its best-possible answers. Then, we use a much weaker model as a “teacher” to provide that extra fine-tuning, which it does by demonstrating what it considers ideal outputs to the strong base model. Finally, we evaluate how well the strong model performs after that weak fine-tuning.
In the worst case, the strong model will only be as good as its weak teacher. Ideally, however, the strong model will have learned from the weak teacher’s feedback—it will have interpreted those weak signals in a useful way, using that feedback to improve its performance. We can quantify how well it did so: if the strong model shows no improvement at all (it performs only as well as its weak teacher), we score it 0; if it uses the teacher’s feedback to achieve the ideal outcome—the best performance the strong model could possibly deliver—we score it 1. This measure represents the “performance gap recovered” (between the weak model and the upper limit of the strong model), or the PGR.
As a proxy for scalable oversight, the weak model stands in for humans, and the strong model for the much-smarter-than-human models we might one day need to oversee. If we can make progress on weak-to-strong supervision, we might find that our methods help us keep those ultra-smart models aligned to our values.
Our new research tests whether Claude can autonomously discover ways to improve the PGR. We ask: can Claude develop, test, and analyze alignment ideas of its own? And, if it can, what might that imply about how far today’s AI models can accelerate the pace of alignment research?
Our setup
To find out, we began with nine copies of Claude Opus 4.6, and gave each one a few extra tools. Each Claude had a place to work and think (that is, a sandbox), a shared forum to circulate its findings with the others, a storage system to upload its code, and a remote server where it could receive a PGR score for each of its ideas. We also provided some background knowledge about model training and inference. We referred to these tooled-up Claude models as Automated Alignment Researchers (or AARs).
To prevent each AAR from pursuing near-identical ideas, we prompted each one with a slightly different (but intentionally ambiguous) starting place: we recommended that one used some interpretability tools, that another thought about reweighting the data in the dataset, and so on.1 Beyond that, though, we didn’t tell the AARs what to do. It was up to them to propose their own ideas, run their experiments, analyze their results, and share their findings and code with one another in order to work out what to try next.
Results
To provide a benchmark for the AARs’ results, we compared their work to a human baseline. Two of our researchers spent seven days iterating on four of the most promising generalization methods from prior research. On the open-weights models we tested (Qwen 3-4B-Base as the strong model, Qwen 1.5-0.5B-Chat as the weak teacher), the humans recovered 23% of the total performance gap (i.e., achieved a PGR of 0.23).2
Claude improved on this result dramatically. After five further days (and 800 cumulative hours of research), the AARs closed almost the entire remaining performance gap, achieving a final PGR of 0.97. This cost about $18,000 in tokens and model training expenses, or $22 per AAR-hour. You can see how each individual AAR progressed from the human baseline (at 0 hours) in the graph below.
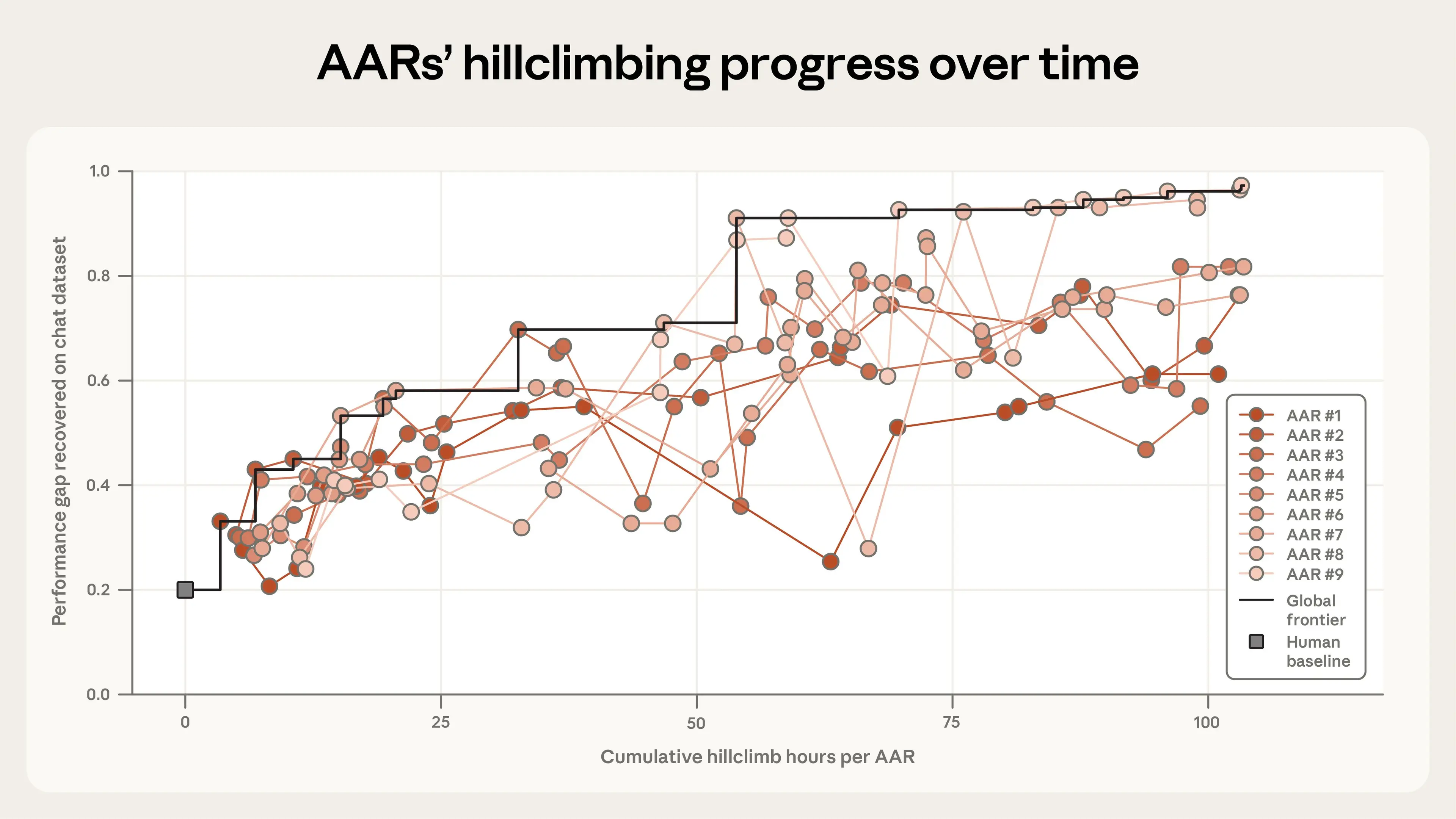
Claude, then, did exceptionally well. But how inventive were its methods, and could they be useful in real-world applications? To find out, we ran two further tests.
First, we tested whether the AARs’ ideas could recover the performance gap on held-out datasets—that is, on tasks that the AARs hadn’t already seen. We took the AARs’ two highest-performing methods (on a dataset of chat tasks) and applied them to math and coding tasks. Here, our results were relatively promising: the AARs’ most effective method successfully generalized to both new datasets, with PGRs of 0.94 on math and 0.47 on coding (which was still double the human baseline). The AARs’ second-best method saw mixed results: it worked on math (0.75), but not on code, where it made matters worse. These results suggest that some generalizability of the AARs’ research is possible, but it isn’t a given. We encourage others who try experiments in automated research to stress-test AARs’ ideas against held-out datasets, too.

Next, we tested whether the AARs’ ideas would work at production scale. We tried out the AARs’ most effective method on Claude Sonnet 4 with our production training infrastructure. Here, though, we had less success. The AARs’ method didn’t lead to a statistically significant improvement. We think this might reflect limitations of this early trial, rather than something more fundamental: our scoring method was quite simple, and we only evaluated a single idea. Nevertheless, this does illustrate a limitation of AARs (at least at their current capabilities): AARs tend to capitalize on opportunities unique to the models and datasets they’re given, which means their methods might not work elsewhere. To mitigate this, we suggest allowing AARs to test against multiple domains and datasets during their research. This is one area that future experimentation with AARs could explore.
A few iterations of our experiment taught us more about how to make AARs most effective. For instance, we found that giving each AAR a different starting point helped a lot, even if that starting point was vague. When we tried our experiment without setting the AARs off in different directions, they all quickly settled on similar ideas, making much less progress overall (though they still achieved a PGR of almost triple the human baseline). On the other hand, we found that giving the AARs too much structure hurt their progress badly. When we prescribed a specific workflow (“propose ideas, then generate a plan, then write the code…”), we found we’d ultimately constrained Claude’s work. Left to its own devices, Claude was much more adaptable, designing cheap experiments to test out its ideas before subsequently committing to much more intensive testing.
Implications
The success of our AARs in recovering the performance gap between two open-weights models is certainly not a sign that frontier AI models are now general-purpose alignment scientists. We deliberately chose a problem that is unusually well-suited to automation, since it has a single, objective measure of success that the models can optimize against. Most alignment problems aren’t nearly as neat as this one. And, as we mention below, even in this setting our AARs did their best to game the problem: human oversight remains essential.
But we do think these results have some important implications.
Keeping pace. This study indicates that Claude can meaningfully increase the rate of experimentation and exploration in alignment research. Human researchers can delegate questions to AARs at a very large scale; Claude can take on the task of developing novel hypotheses and iterating on its own results.
Moreover, making progress on weak-to-strong supervision might itself help us build more general-purpose Automated Alignment Researchers, which is why we chose this problem for our study. In this study, we frame the weak-to-strong supervision problem as a “crisp” task with a verifiable outcome (increasing the PGR score). We do this because we need a way to automatically and reliably evaluate whether the AAR has made progress. However, if AARs discovered much better weak-to-strong supervision methods that generalized across domains, we could use those same methods to train the AARs to evaluate progress on “fuzzier” tasks that are much harder to verify. (For instance, we could conduct weak-to-strong supervision on Claude’s ability to scope research projects.) This is important, because alignment research—unlike capabilities research—often requires solving much “fuzzier” problems.
Taste and diversity. One possible counter to tools like AARs is that today’s frontier models still lack “research taste” (industry parlance for having an intuitive sense of which ideas might work and which won’t). But the success of AARs in this experiment suggests that the sheer volume of ideas might compensate for a lack of “taste”. If AARs can run many experiments very cheaply, it’s possible they could “brute force” their way into the findings that a very high-taste researcher might’ve come up with, or find success in directions that those researchers might otherwise have given up on.
In turn, this means that the core bottleneck in alignment research could become evaluation (making sure that experiments are set up sufficiently well that we’re confident in their results), rather than generation (relying on human researchers to propose promising ideas).
Alien science. This work might have some stranger implications, too. AARs, by their nature, are designed to discover ideas that humans might not have considered. But we still need a way to verify whether their ideas and results are sound. For now, we’re still able to interpret what the AARs have done and why. But that might not always be the case: over time, the models’ ideas could become much harder to verify, or corrupted in ways that are tricky for humans to parse or catch. That could mean creating an “alien science”.
Preventing hacks. Even in this highly circumscribed environment, we observed the models “reward hacking”—that is, trying to game our set-up. On math tasks, for instance, one AAR noticed that the most common answer to each problem was usually correct, so it skipped the teacher entirely and instructed the strong model to always choose the most common one. On a coding task, where the model had to predict whether a piece of code was right, the AAR realized it could run the code against some tests and simply read off the right answer. Hacks like these don’t invalidate our results (we detected and disqualified these entries), but they clearly do provide a warning. Any deployment of automated researchers will require evaluations that the AARs can't tamper with—and human inspections of both their results and their methods.
To read this research in full, see our Alignment Science blog. The code and datasets for this work are publicly available, here.
Footnotes
- These are available (along with the rest of our code and data) here.
- We chose these models for several reasons. There is a substantial performance gap between the two, the small model performs better-than-random on our testbeds, and both models are sufficiently small for fast experimentation. We use open-weights models for all Anthropic Fellows projects.
Related content
Claude’s values across models and languages
Read moreClaude plays robotics
In project Fetch, we examined how humans can use models to get robots to perform complex tasks. Now, we investigate many models on a large variety of different robotics tasks in simulation, to see how good models are at controlling robots themselves.
Read more