Challenges in red teaming AI systems

In this post we detail insights from a sample of red teaming approaches that we’ve used to test our AI systems. Through this practice, we’ve begun to gather empirical data about the appropriate tool to reach for in a given situation, and the associated benefits and challenges with each approach. We hope this post is helpful for other companies trying to red team their AI systems, policymakers curious about how red teaming works in practice, and organizations that want to red team AI technology.
What is red teaming?
Red teaming is a critical tool for improving the safety and security of AI systems. It involves adversarially testing a technological system to identify potential vulnerabilities. Today, researchers and AI developers employ a wide range of red teaming techniques to test their AI systems, each with its own advantages and disadvantages.
The lack of standardized practices for AI red teaming further complicates the situation. Developers might use different techniques to assess the same type of threat model, and even when they use the same technique, the way they go about red teaming might look quite different in practice. This inconsistency makes it challenging to objectively compare the relative safety of different AI systems.
To address this, the AI field needs established practices and standards for systematic red teaming. We believe it is important to do this work now so organizations are prepared to manage today’s risks and mitigate future threats when models significantly increase their capabilities. In an effort to contribute to this goal, we share an overview of some of the red teaming methods we have explored, and demonstrate how they can be integrated into an iterative process from qualitative red teaming to the development of automated evaluations. We close with a set of recommended actions policymakers can take to foster a strong AI testing ecosystem.
Red teaming methods this post covers:
Domain-specific, expert red teaming
- Trust & Safety: Policy Vulnerability Testing
- National security: Frontier threats red teaming
- Region-specific: Multilingual and multicultural red teaming
Using language models to red team
- Automated red teaming
Red teaming in new modalities
- Multimodal red teaming
Open-ended, general red teaming
- Crowdsourced red teaming for general harms
- Community-based red teaming for general risks and system limitations
In the following sections, we will cover each of these red teaming methods, examining the unique advantages and the challenges they present (some of the benefits and challenges we outline may be applicable across red teaming methods).
Domain-specific, expert teaming
At a high level, domain-specific expert teaming involves collaborating with subject matter experts to identify and assess potential vulnerabilities or risks in AI systems within their area of expertise. Enlisting experts helps bring a deeper understanding of complex, context-specific issues.
Policy Vulnerability Testing for Trust & Safety risks
High-risk threats, such as those that pose severe harm to people or negatively impact society, warrant sophisticated red team methods and collaboration with external subject matter experts. Within the Trust & Safety space, we adopt a form of red teaming called “Policy Vulnerability Testing” (PVT). PVT is a form of in-depth, qualitative testing we conduct in collaboration with external subject matter experts on a variety of policy topics covered under our Usage Policy. We work with experts such as Thorn on issues of child safety, Institute for Strategic Dialogue on election integrity, Global Project Against Hate and Extremism on radicalization, among others.
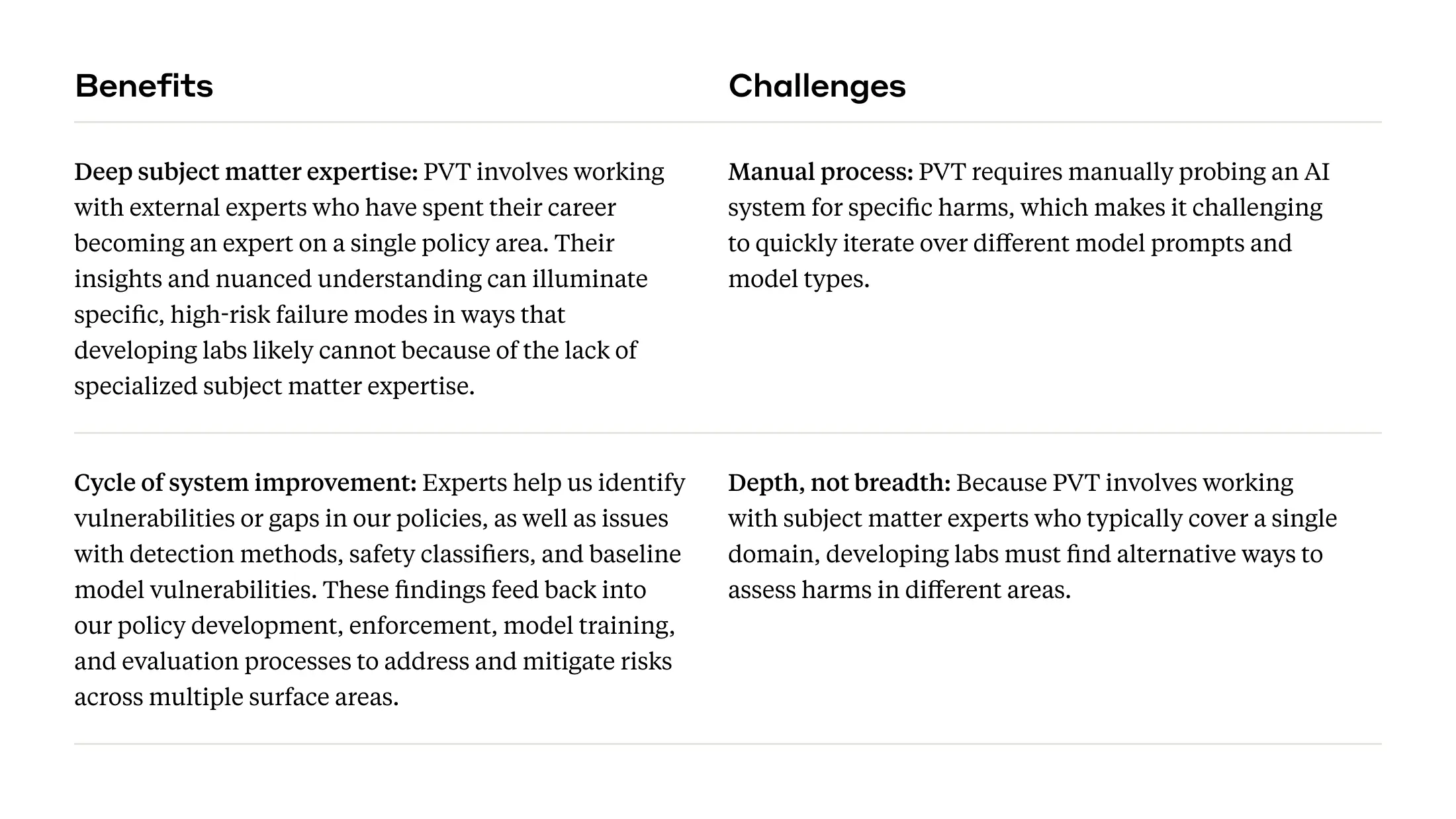
Frontier threats red teaming for national security risks
Since we released our blog post on our approach to red teaming AI systems for national security risks, we’ve continued to build out evaluation techniques to measure “frontier threats” (areas that may pose a consequential risk to national security), as well as the external partnerships that bring deep subject matter expertise to red teaming our systems. Our frontier red teaming work primarily focuses on Chemical, Biological, Radiological, and Nuclear (CBRN), cybersecurity, and autonomous AI risks. We work with experts in these domains to both test our systems and co-design new evaluation methods. Depending on the threat model, external red teamers might work with our standard deployed versions of Claude to investigate risks in “real-world” settings, or they might work with non-commercial versions that use a different set of risk mitigations.

Multilingual and multicultural red teaming
The majority of our red teaming work takes place in English and typically from the perspective of people based in the United States. One method to better understand, and ideally address, this lack of representation is by red teaming in other languages and cultural contexts. Capacity building efforts led by the public sector can encourage local populations to test AI systems for language skills and topics relevant to a specific community. As one example, we were pleased to partner with Singapore’s Infocomm Media Development Authority (IMDA) and AI Verify Foundation on a red teaming project across four languages (English, Tamil, Mandarin, and Malay) and topics relevant to a Singaporean audience and user base. We look forward to IMDA and AI Verify Foundation publishing more on this work and insights from red teaming more broadly.

Using language models to red team
Using language models to red team involves leveraging the capabilities of AI systems to automatically generate adversarial examples and test the robustness of other AI models, potentially complementing manual testing efforts and enabling more efficient and comprehensive red teaming.
Automated red teaming
As models become more capable, we’re interested in ways we might use them to complement manual testing with automated red teaming performed by models themselves. Specifically, we hope to understand how effective red teaming might be for reducing harmful behavior. To do this, we employ a red team / blue team dynamic, where we use a model to generate attacks that are likely to elicit the target behavior (red team) and then fine-tune a model on those red teamed outputs in order to make it more robust to similar types of attack (blue team). We can run this process repeatedly to devise new attack vectors and, ideally, make our systems more robust to a range of adversarial attacks.

Red teaming in new modalities
Red teaming in new modalities involves testing AI systems that can process and respond to various forms of input (such as images or audio), which can help identify novel risks and failure modes associated with these expanded capabilities before systems are deployed.
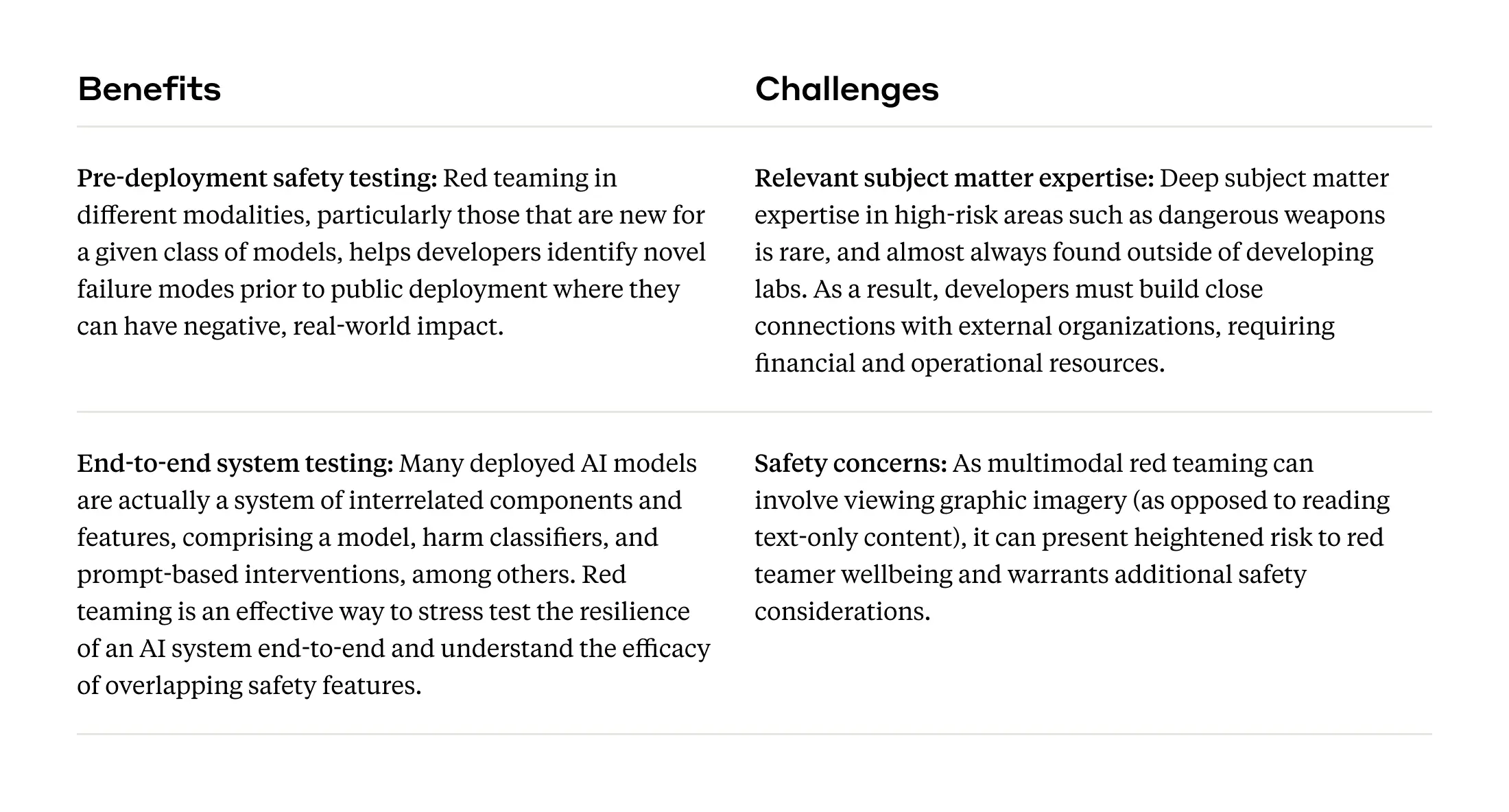
Multimodal red teaming
The Claude 3 family of models are multimodal—while they do not generate images, they can take in visual information (e.g., photos, sketches, charts) and provide text-based outputs in response, a capability that presents potential new risks (e.g., fraudulent activity, threats to child safety, violent extremism, etc.). Prior to deploying Claude 3, our Trust & Safety team red teamed our systems for image and text-based risks, and also worked with external red teamers to assess how well our models refuse to engage with harmful inputs (both image and text). Pre-deployment red teaming is critical for any release, especially those that include new model capabilities and modalities.
Open-ended, general red teaming
Crowdsourced red teaming for general harms
When we began our red teaming research efforts in mid-2022, there was a large body of literature on red teaming software systems for security vulnerabilities, but relatively little in the way of standards for red teaming language models. Our work here took place purely in a research capacity (we hadn’t yet released our AI Assistant, Claude), so we opted to work with crowdworkers in a closely controlled environment and asked them to use their own judgment and risk tolerance for attack types, rather than asking them to red team for specific threats.

Community red teaming for general risks and system limitations
As red teaming AI models has become more common, efforts such as DEF CON’s AI Village have engaged a broader cross-section of society in the testing of publicly deployed systems. In 2023, the Generative Red Teaming (GRT) Challenge hosted thousands of participants from a broad range of ages and disciplines, including many individuals with nontechnical backgrounds, and invited them to red team models provided by Anthropic and other labs. We were impressed by the enthusiasm and creativity red teamers brought to the challenge, and hope that the GRT challenge and events like it can inspire a more diverse group of people to get involved in AI safety efforts.
Having explored these diverse red teaming methods, each with their own strengths and challenges, we now discuss how they can contribute to our goal of establishing more standardized red teaming practices in the AI industry.

How do we go from qualitative red teaming to quantitative evaluations?
In addition to illuminating potential risks, the red teaming practices above can serve as a precursor to building automated, quantitative evaluation methods. This is a meta-challenge for the red teaming field: how do you turn the results of red teaming into something which can create compounding value for the organization whose systems are being red teamed? Ideally, red teaming is part of an iterative loop that includes assessing an AI model (both manually and using automated techniques) for various risks, implementing corresponding mitigations, and testing the efficacy of those guardrails.
At the beginning of the process, subject matter experts develop a well-articulated description of a potential threat model and then probe an AI model in an attempt to elicit said threats in an ad hoc way. As red teamers develop a deeper sense of the problem space, they begin to standardize their red teaming practices, modifying inputs to elicit harmful behavior more effectively.
From there, we can use a language model to generate hundreds or thousands of variations of those inputs to cover more surface area, and do so in a fraction of the time. Through this process we go from ad hoc, qualitative human testing, to more thorough, quantitative, and automated testing. We’ve adopted this iterative approach to develop scalable evaluations in our frontier threats red teaming work on national security risks and our Policy Vulnerability Testing for election integrity risks, and we’re eager to apply it to other threat models.
Policy recommendations
To support further adoption and standardization of red teaming, we encourage policymakers to consider the following proposals:
- Fund organizations such as the National Institute of Standards and Technology (NIST) to develop technical standards and common practices for how to red team AI systems safely and effectively.
- Fund the development and ongoing operations of independent government bodies and non-profit organizations that can partner with developers to red team systems for potential risks in a variety of domains. For example, for national security-relevant risks, much of the required expertise will reside within government agencies.
- Encourage the development and growth of a market for professional AI red teaming services, and establish a certification process for organizations that conduct AI red teaming according to shared technical standards.
- Encourage AI companies to allow and facilitate third-party red teaming of their AI systems by vetted (and eventually, certified) outside groups. Develop standards for transparency and model access to enable this under safe and secure conditions.
- Encourage AI companies to tie their red teaming practices to clear policies on the conditions they must meet to continue scaling the development and/or release of new models (e.g., the adoption of commitments such as a Responsible Scaling Policy).
Conclusion
Red teaming is a valuable technique for identifying and mitigating risks in AI systems. The various red teaming methods covered in this post highlight a handful of techniques available for different use cases and threat models. We look forward to collaborating with other actors to iterate on these techniques and work towards common standards for safety testing. By investing in red teaming, we can work towards building AI systems that are safe and beneficial to society. It is one of several tools in a larger effort to ensure AI is developed thoughtfully and with robust safeguards in place.
Related content
Anthropic opens Seoul office and announces new partnerships across the Korean AI ecosystem
Read moreStatement on the US government directive to suspend access to Fable 5 and Mythos 5
The US government has issued an export control directive to suspend all access to Fable 5 and Mythos 5.
Read more