Prompt engineering for Claude's long context window

Claude’s 100,000 token long context window enables the model to operate over hundreds of pages of technical documentation, or even an entire book. As we continue to scale the Claude API, we’re seeing increased demand for prompting guidance on how to maximize Claude’s potential. Today, we’re pleased to share a quantitative case study on two techniques that can improve Claude’s recall over long contexts:
- Extracting reference quotes relevant to the question before answering
- Supplementing the prompt with examples of correctly answered questions about other sections of the document
Let’s get into the details.
Testing long context recall: Multiple choice Q&A
Our goal with this experiment is to evaluate techniques to maximize Claude’s chance of correctly recalling a specific piece of information from a long document.
As the underlying data source for our testing, we used a daily-issue, publicly available government document that contains the meeting transcripts and activities of many different departments. We chose a document from July 13, which is after Claude’s training data cutoff. This minimizes the chance that Claude already knows the information in the document.
In order to generate a dataset of question and answer (Q&A) pairs, we used an approach we call “randomized collage”. We split the document into sections and used Claude to generate five multiple choice questions for each section, each with three wrong answers and one right answer. We then reassembled randomized sets of these sections into long documents so that we could pass them to Claude and test its recall of their contents.
Prompting Claude to generate multiple choice questions
Getting Claude to write your evaluations (evals) for you is a powerful tool and one that we as a prompt engineering team use often. However, it takes careful prompting to get Claude to write questions in the sweet spot of difficulty. Here are some challenges we worked through along the way to designing an effective test suite:
- Claude may propose questions that it can answer off the top of its head without reference to any document, like “What does the Department of Transportation do?”
- Claude may include questions that it struggles to answer correctly, even in short context situations. For example, because Claude sees the world in terms of tokens, not words, a question like “How many words are in the passage?” tends to give Claude trouble.
- Claude may leave unintentional clues in its answers that make the correct answer easy to guess. Notably, we noticed its default was to make the right answer very detailed in comparison to the wrong answers.
- Claude may reference “this document” or “this passage” without specifying what passage it means. This is problematic because when we stitch together multiple documents to form the long context, Claude has no way to know which document the question is asking about.
- There’s also the risk of going too far and making the questions so explicit that they contain the answer. For example, “What is the publication date of the Department of the Interior’s July 2, 2023 notice about additional in-season actions for fisheries?” would be an ineffective question.
To help navigate these pitfalls, we used a prompt template that includes two sample meeting chunks along with hand-written questions to act as few-shot question writing examples, as well as some writing guidelines to get Claude to specify details about the passage. The template and all other prompts used in this experiment are available here.
Evaluation
For this evaluation, we primarily focused on our smaller Claude Instant model (version 1.2) as opposed to our Claude 2 model. This is for a couple of reasons. First, Claude 2 is already very good at recalling information after reading very long documents. Claude Instant needs more help, which makes it easy to see when changes to prompting improve performance. Additionally, Claude Instant is so fast that you can reproduce these evals yourself with the notebook we share.
When provided with only the exact passage Claude used to write the question, Claude Instant was able to answer its own generated question about 90% of the time. We discarded the 10% of questions it answered incorrectly – since Claude was getting them wrong even in a short-context situation, they’re too difficult to be useful for testing long context.1
We also tested Claude’s recall when given a random section not containing the question’s source material. Theoretically, with three wrong answers, Claude should be able to guess the right answer only 25% of the time. In practice, it guessed right 34% of the time; above chance, but not too much so. Claude is likely sometimes intuiting the right answer based on its general knowledge, or based on subtle cues in the answer.
In order to build long documents from shorter chunks, we artificially generated a new long context for each question by stitching together a random assortment of passages until we reached the desired number of tokens. We tested Claude on stitched-together documents containing roughly 75,000 and 90,000 tokens.
This patchwork context formation is why Claude referencing ambiguous phrases like “this document” or “this passage” in its question was causing problems. A question like “What is the publication date of this notice?” ceases to be answerable when there are a dozen different notices in the context to which “this notice” could refer. This is why our question generation prompt includes language telling Claude to be explicit about the passage to which the question refers – for example, “What is the publication date of the notice about additional in-season actions for fisheries?"
After generating the long documents (collages), we tested Claude’s recall using four different prompting strategies:
- Base – just ask Claude to answer
- Nongov examples - Give Claude two fixed examples of correctly answered general knowledge multiple choice questions that are unrelated to the government document2
- Two examples - Give Claude two examples of correctly answered multiple choice questions, dynamically chosen at random from the set of Claude-generated questions about other chunks in the context
- Five examples - Same strategy as #3, but with five examples
For each of the four strategies above, we also tested them with and without the use of a <scratchpad>, in which we instruct Claude to pull relevant quotes. Furthermore, we tested each of these strategies with the passage containing the answer positioned either at the beginning, the end, or in the middle of the input. Finally, to get a sense of the effect of context length on the results, we tested with both 70K and 95K token documents.
We used Claude Instant 1.2 for the above test. We also show results for Claude 2 on the baseline strategy and the strategy that performed best for Claude Instant 1.2.
Results
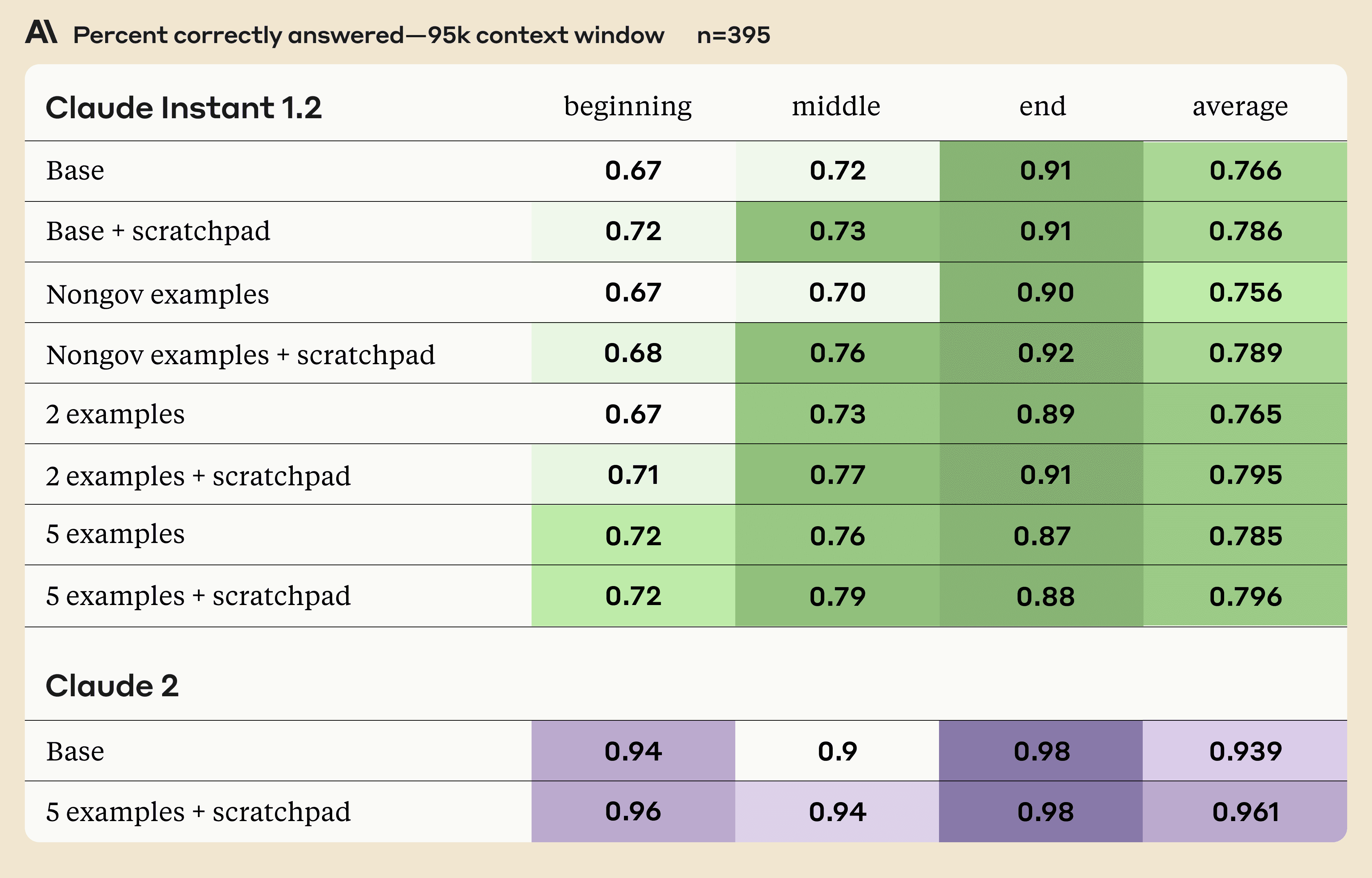
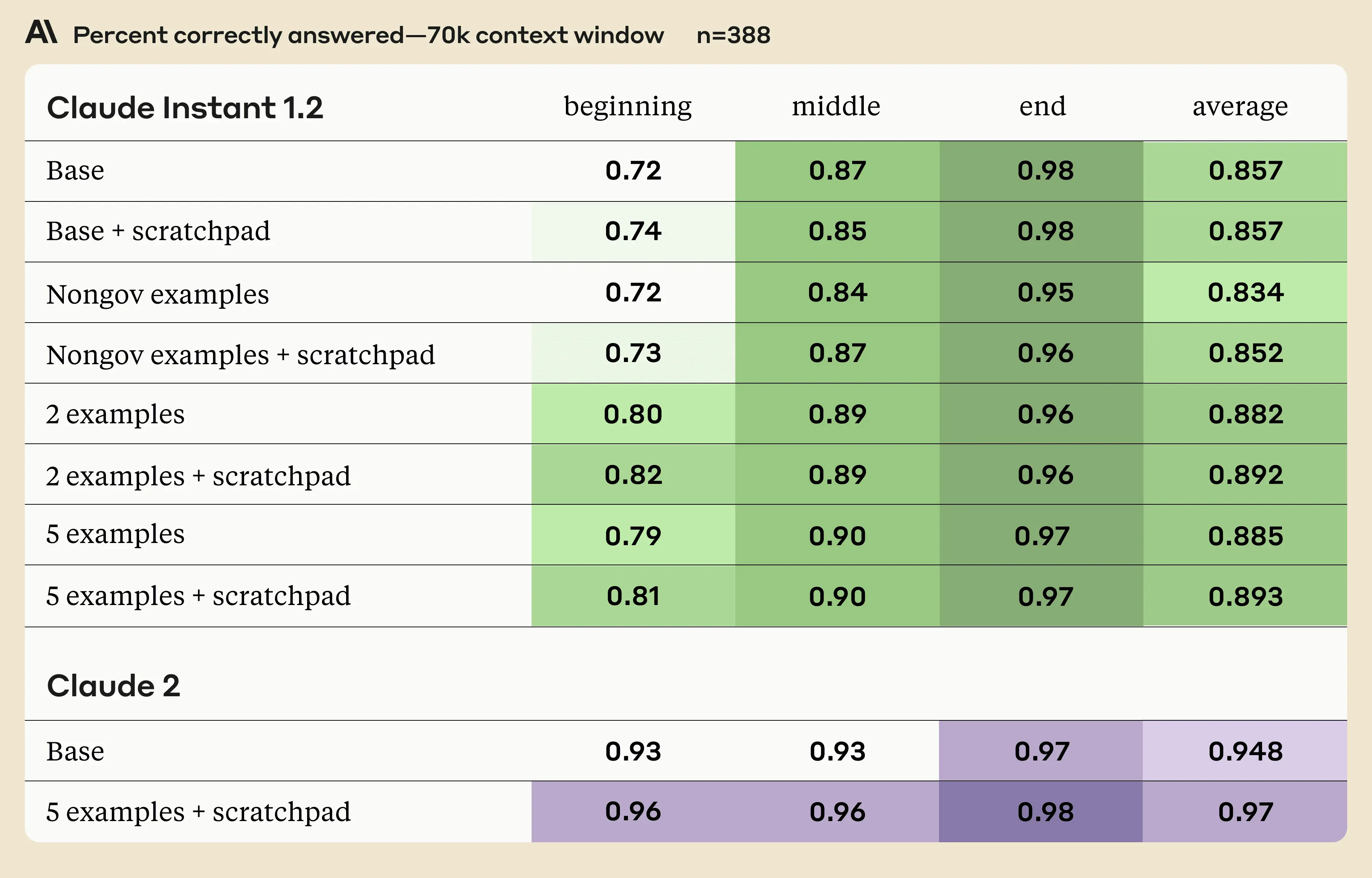
Some notes on the experiment:
- While performance on the beginning and middle of the doc are substantially improved by the use of a scratchpad and examples, performance on the end can be degraded. This could be because the addition of the examples in the prompt increases the distance between the very end of the document (where the relevant information is) and when Claude needs to answer it. This is likely of only minor concern as only a small fraction of the data in the source document is at the very end. However, it does emphasize the importance of putting the instructions at the end of the prompt, as we want Claude’s recall of them to be as high as possible.
- Claude 2’s improvement from 0.939 to 0.961 with prompting might seem small in absolute terms, but it reflects a 36% reduction in errors.
Some takeaways you can use for writing your long-context Q&A prompts:
- Use many examples and the scratchpad for best performance on both context lengths.
- Pulling relevant quotes into the scratchpad is helpful in all head-to-head comparisons. It comes at a small cost to latency, but improves accuracy. In Claude Instant’s case, the latency is already so low that this shouldn’t be a concern.
- Contextual examples help on both 70K and 95K, and more examples is better.
- Generic examples on general/external knowledge do not seem to help performance.
For Claude Instant, there seems to be a monotonic inverse relationship between performance and the distance of the relevant passage to the question and the end of the prompt, while Claude 2 performance on 95K sees a small dip in the middle.3
Introducing the new Anthropic Cookbook
Fully reproducible code for this experiment is live in the new Anthropic Cookbook. This growing set of resources also contains two other recipes at the moment:
- A Search and Retrieval demo showcasing a tool use flow for searching Wikipedia.
- Guidance on implementing mock-PDF uploading functionality via the Anthropic API.
We’re looking forward to expanding the Anthropic Cookbook and our other prompt engineering resources in the future, and we hope they inspire you to dream big about what you can build with Claude. If you haven’t received access to the Claude API yet, please register your interest.
Footnotes
1A common theme in the questions Claude gets wrong is counting, e.g. “What is the estimated number of responses per respondent that the notice states for each form in the Common Forms Package for Guaranteed Loan Forms?” and “How many proposed finished products are listed in the notification for production activity at the Getinge Group Logistics Americas LLC facility?” Notably, on some of these questions, Claude’s pre-specified “correct” answer (from when it generated the QA pairs) is not in reality correct. This is a source of noise in this experiment.
2The questions are: 1. Who was the first president of the United States? A. Thomas Jefferson, B. George Washington, C. Abraham Lincoln, D. John Adams, 2. What is the boiling temperature of water, in degrees Fahrenheit? A. 200, B. 100, C. 287, D. 212.
3A recent paper found a U-shaped relationship between performance and location in the context for a similar task. A possible explanation for the differing results is that the examples in the paper have avg. length 15K tokens (Appendix F), compared to 70K/95K here.