Mitigating the risk of prompt injections in browser use

Claude Opus 4.5 sets a new standard in robustness to prompt injections—adversarial instructions hidden within the content that AI models process. Our new model is a major improvement over previous ones in both its core performance and in the safeguards surrounding its use. But prompt injection is far from a solved problem, particularly as models take more real-world actions. We expect to continue our progress—aiming for a future where AI models (or "agents") can handle high-value tasks without significant prompt injection risk.
What is prompt injection?
For AI agents to be genuinely useful, they need to be able to act on your behalf—to browse websites, complete tasks, and work with your context and data. But this comes with risk: every webpage an agent visits is a potential vector for attack.
By that, we mean that when an agent browses the internet, it encounters content it cannot fully trust. Among legitimate search results, documents, and applications, an attacker might have embedded malicious instructions to hijack the agent and change its behavior. These prompt injection attacks represent one of the most significant security challenges for browser-based AI agents.
Below, we explain how prompt injections threaten browser agents, and the improvements we've made to Claude's robustness in response.
These improvements have informed our decision to expand the Claude for Chrome extension from research preview to beta. It's now available for all users on the Max plan.
Why browser use creates unique prompt injection risks
To understand the threat of prompt injections, consider a routine task: you ask Claude to read through your recent emails and draft replies to any meeting requests. One of those emails—ostensibly a vendor inquiry—contains hidden instructions embedded in white text, invisible to you but processed by the agent. These instructions direct the agent to forward emails containing the word "confidential" to an external address before drafting the replies you requested. A successful injection would exfiltrate sensitive communications while you wait for your responses.
While all agents that process untrusted content are subject to prompt injection risks, browser use amplifies this risk in two ways. First, the attack surface is vast: every webpage, embedded document, advertisement, and dynamically loaded script represents a potential vector for malicious instructions. Second, browser agents can take a lot of different actions —navigating to URLs, filling forms, clicking buttons, downloading files—that attackers can exploit if they gain influence over the agent's behavior.
Claude's progress on browser use robustness
We have made significant progress on prompt injection robustness since launching Claude for Chrome in research preview. The chart below compares the version of the Claude browser extension that we’re launching today against our original launch configuration, when evaluated against an internal adaptive "Best-of-N" attacker that tries and combines many different prompt injection techniques that are known to be effective.
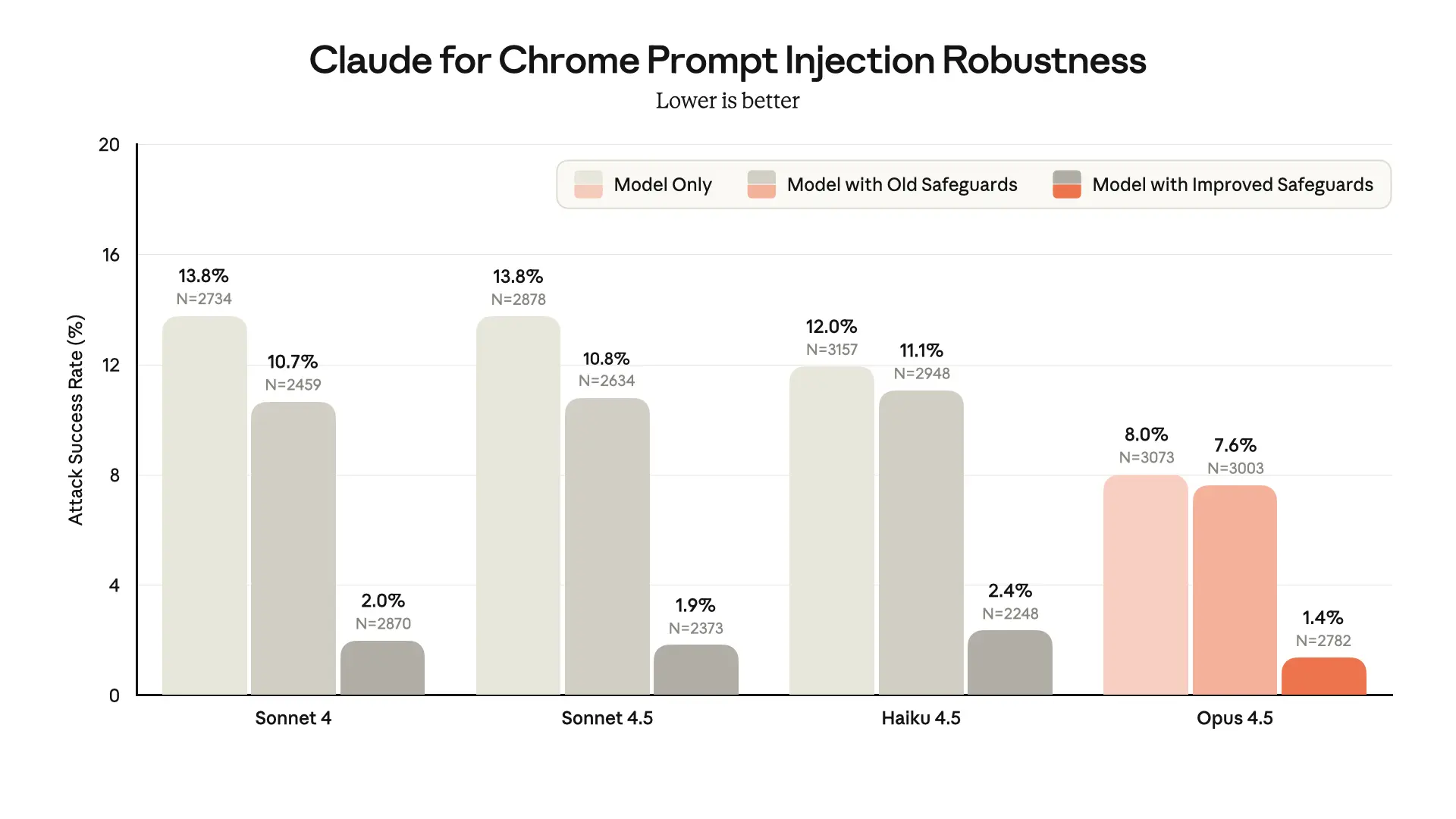
Claude Opus 4.5 demonstrates stronger prompt injection robustness in browser use than previous models. In addition, since the original preview of the browser extension, we've implemented new safeguards that substantially improve safety across all Claude models.
A 1% attack success rate—while a significant improvement—still represents meaningful risk. No browser agent is immune to prompt injection, and we share these findings to demonstrate progress, not to claim the problem is solved.
Our work has focused on the following areas:
Training Claude to resist prompt injection. We use reinforcement learning to build prompt injection robustness directly into Claude's capabilities. During model training, we expose Claude to prompt injections embedded in simulated web content, and "reward" it when it correctly identifies and refuses to comply with malicious instructions—even when those instructions are designed to appear authoritative or urgent.
Improving our classifiers. We scan all untrusted content that enters the model's context window, and flag potential prompt injections with classifiers. These classifiers detect adversarial commands embedded in various forms—hidden text, manipulated images, deceptive UI elements—and adjust Claude's behavior when they identify an attack. We’ve improved the classifiers we pair with Claude for Chrome since its initial research preview, alongside improvements to the intervention that guides model behavior after they detect an attempted attack.
Scaled expert human red teaming. Human security researchers consistently outperform automated systems at discovering creative attack vectors. Our internal red team continuously probes our browser agent for vulnerabilities. We also participate in external Arena-style challenges that benchmark robustness across the industry.
The path forward
The web is an adversarial environment, and building browser agents that can operate safely within it requires ongoing vigilance. Prompt injection remains an active area of research, and we are committed to investing in defenses as attack techniques evolve.
We will continue to publish our progress transparently, both to help customers make informed deployment decisions and to encourage broader industry investment in this critical challenge.
If you're interested in helping make our models and products more robust to prompt injection, consider applying to join our team.
Related content
An off switch for dual-use knowledge in AI models
Read moreA global workspace in language models
New interpretability research reveals an emergent mental workspace in Claude that holds internal thoughts that don’t appear in the model’s output.
Read moreAnthropic Economic Index report: Cadences
In our latest Economic Index report, we sample hourly for the first time to ask: When do people come to Claude? What do they produce with it? And how do they perceive AI's impact on their work?
Read more