Introducing Claude Haiku 4.5

Claude Haiku 4.5, our latest small model, is available today to all users.
What was recently at the frontier is now cheaper and faster. Five months ago, Claude Sonnet 4 was a state-of-the-art model. Today, Claude Haiku 4.5 gives you similar levels of coding performance but at one-third the cost and more than twice the speed.
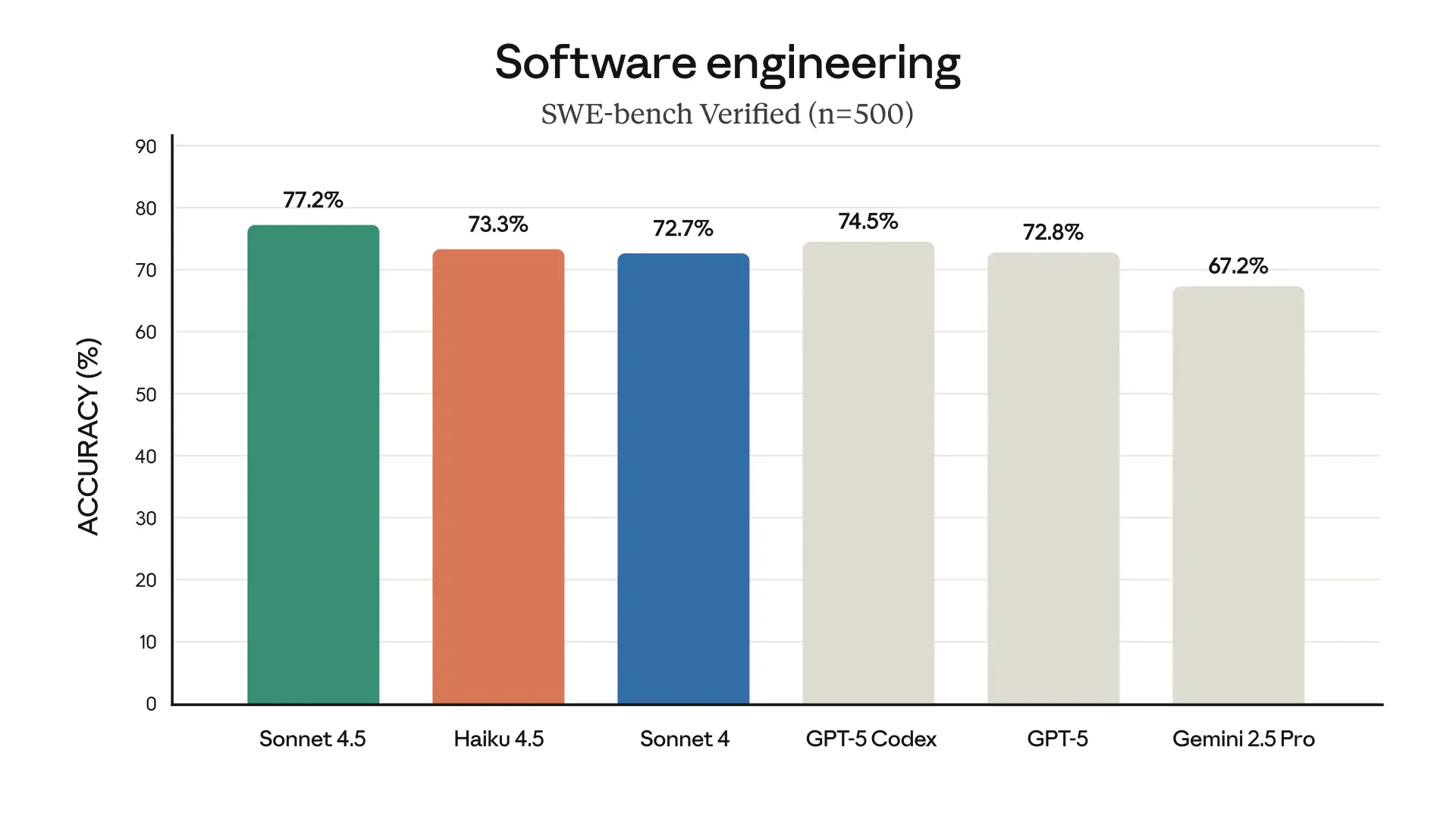
Claude Haiku 4.5 even surpasses Claude Sonnet 4 at certain tasks, like using computers. These advances make applications like Claude for Chrome faster and more useful than ever before.
Users who rely on AI for real-time, low-latency tasks like chat assistants, customer service agents, or pair programming will appreciate Haiku 4.5’s combination of high intelligence and remarkable speed. And users of Claude Code will find that Haiku 4.5 makes the coding experience—from multiple-agent projects to rapid prototyping—markedly more responsive.
Claude Sonnet 4.5, released two weeks ago, remains our frontier model and the best coding model in the world. Claude Haiku 4.5 gives users a new option for when they want near-frontier performance with much greater cost-efficiency. It also opens up new ways of using our models together. For example, Sonnet 4.5 can break down a complex problem into multi-step plans, then orchestrate a team of multiple Haiku 4.5s to complete subtasks in parallel.
Claude Haiku 4.5 is available everywhere today. If you’re a developer, simply use claude-haiku-4-5 via the Claude API. Pricing is now $1/$5 per million input and output tokens.
Benchmarks
Claude Haiku 4.5 hit a sweet spot we didn't think was possible: near-frontier coding quality with blazing speed and cost efficiency. In Augment's agentic coding evaluation, it achieves 90% of Sonnet 4.5's performance, matching much larger models. We're excited to offer it to our users.
Claude Haiku 4.5 is a leap forward for agentic coding, particularly for sub-agent orchestration and computer use tasks. The responsiveness makes AI-assisted development in Warp feel instantaneous.
Historically models have sacrificed speed and cost for quality. Claude Haiku 4.5 is blurring the lines on this trade off: it's a fast frontier model that keeps costs efficient and signals where this class of models is headed.
Claude Haiku 4.5 delivers intelligence without sacrificing speed, enabling us to build AI applications that utilize both deep reasoning and real-time responsiveness.
Claude Haiku 4.5 is remarkably capable—just six months ago, this level of performance would have been state-of-the-art on our internal benchmarks. Now it runs up to 4-5 times faster than Sonnet 4.5 at a fraction of the cost, unlocking an entirely new set of use cases.
Speed is the new frontier for AI agents operating in feedback loops. Haiku 4.5 proves you can have both intelligence and rapid output. It handles complex workflows reliably, self-corrects in real-time, and maintains momentum without latency overhead. For most development tasks, it's the ideal performance balance.
Claude Haiku 4.5 outperformed our current models on instruction-following for slide text generation, achieving 65% accuracy versus 44% from our premium tier model—that's a game-changer for our unit economics.
Our early testing shows that Claude Haiku 4.5 brings efficient code generation to GitHub Copilot with comparable quality to Sonnet 4 but at faster speed. Already we're seeing it as an excellent choice for Copilot users who value speed and responsiveness in their AI-powered development workflows.
Safety evaluations
We ran a detailed series of safety and alignment evaluations on Claude Haiku 4.5. The model showed low rates of concerning behaviors, and was substantially more aligned than its predecessor, Claude Haiku 3.5. In our automated alignment assessment, Claude Haiku 4.5 also showed a statistically significantly lower overall rate of misaligned behaviors than both Claude Sonnet 4.5 and Claude Opus 4.1—making Claude Haiku 4.5, by this metric, our safest model yet.
Our safety testing also showed that Claude Haiku 4.5 poses only limited risks in terms of the production of chemical, biological, radiological, and nuclear (CBRN) weapons. For that reason, we’ve released it under the AI Safety Level 2 (ASL-2) standard—compared to the more restrictive ASL-3 for Sonnet 4.5 and Opus 4.1. You can read the full reasoning behind the model’s ASL-2 classification, as well as details on all our other safety tests, in the Claude Haiku 4.5 system card.
Further information
Claude Haiku 4.5 is available now on Claude Code and our apps. Its efficiency means you can accomplish more within your usage limits while maintaining premium model performance.
Developers can use Claude Haiku 4.5 on our API, Amazon Bedrock, and Google Cloud’s Vertex AI, where it serves as a drop-in replacement for both Haiku 3.5 and Sonnet 4 at our most economical price point.
For complete technical details and evaluation results, see our system card, model page, and documentation.
Methodology
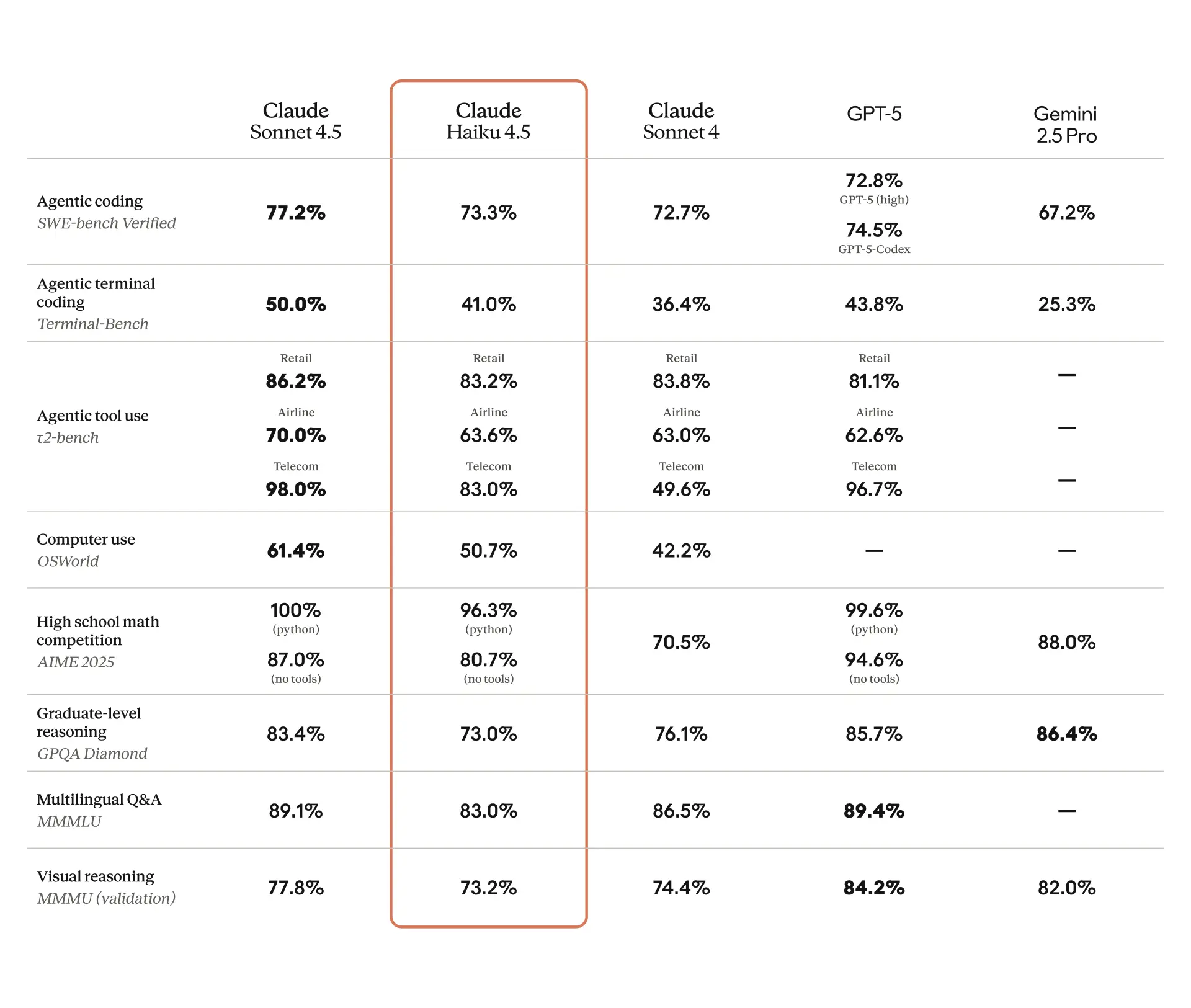
- SWE-bench Verified: All Claude results were reported using a simple scaffold with two tools—bash and file editing via string replacements. We report 73.3%, which was averaged over 50 trials, no test-time compute, 128K thinking budget, and default sampling parameters (temperature, top_p) on the full 500-problem SWE-bench Verified dataset.
- The score reported uses a minor prompt addition: "You should use tools as much as possible, ideally more than 100 times. You should also implement your own tests first before attempting the problem."
- Terminal-Bench: All scores reported use the default agent framework (Terminus 2), with XML parser, averaging 11 runs (6 without thinking (40.21% score), 5 with 32K thinking budget (41.75% score)) with n-attempts=1.
- τ2-bench: Scores were achieved averaging over 10 runs using extended thinking (128k thinking budget) and default sampling parameters (temperature, top_p) with tool use and a prompt addendum to the Airline and Telecom Agent Policy instructing Claude to better target its known failure modes when using the vanilla prompt. A prompt addendum was also added to the Telecom User prompt to avoid failure modes from the user ending the interaction incorrectly.
- AIME: Haiku 4.5 score reported as the average over 10 independent runs that each calculate pass@1 over 16 trials with default sampling parameters (temperature, top_p) and 128K thinking budget.
- OSWorld: All scores reported use the official OSWorld-Verified framework with 100 max steps, averaged across 4 runs with 128K total thinking budget and 2K thinking budget per-step configured.
- MMMLU: All scores reported are the average of 10 runs over 14 non-English languages with a 128K thinking budget.
- All other scores were averaged over 10 runs with default sampling parameters (temperature, top_p) and 128K thinking budget.
All OpenAI scores reported from their GPT-5 post, GPT-5 for developers post, GPT-5 system card (SWE-bench Verified reported using n=500), and Terminal Bench leaderboard (using Terminus 2). All Gemini scores reported from their model web page, and Terminal Bench leaderboard (using Terminus 1).
Related content
Introducing Claude Sonnet 5
Sonnet 5 delivers frontier performance across coding, agents, and professional work at scale.
Read moreRedeploying Fable 5
Fable 5 returns globally July 1. We're also proposing an industry-wide framework for scoring jailbreak severity, together with Amazon, Microsoft, Google, and other Glasswing partners.
Read moreClaude Science, an AI workbench for scientists, is now available
Claude Science is a customizable app that integrates the tools and packages researchers most often use, produces auditable artifacts, and provides flexible access to computing resources.
Read more