Claude Sonnet 4.6


Hybrid reasoning model with fast, capable intelligence for real-time agents and high-volume work, featuring a 1M context window
Announcements
- NEW
Claude Sonnet 5
Jun 30, 2026
Our most agentic Sonnet yet. It brings performance that recently required larger, more expensive models to coding, tool use, and everyday work, at Sonnet’s speed and price.
Read more
Claude Sonnet 4.6
Feb 17, 2026
Sonnet 4.6 delivers frontier performance across coding, agents, and professional work at scale. It can compress multi-day coding projects into hours and deliver production-ready solutions.
Read more
Claude Sonnet 4.5
Sep 29, 2025
Sonnet 4.5 is the best model in the world for agents, coding, and computer use. It’s also our most accurate and detailed model for long-running tasks, with enhanced domain knowledge in coding, finance, and cybersecurity.
Read more
Claude Sonnet 4
May 22, 2025
Sonnet 4 improves on Sonnet 3.7 across a variety of areas, especially coding. It offers frontier performance that’s practical for most AI use cases, including user-facing AI assistants and high-volume tasks.
Read more
Availability and pricing
Anyone can chat with Claude using Sonnet 5 on Claude.ai, available on web, iOS, and Android.
For developers interested in building agents, Sonnet 5 is available on the Claude Platform natively, and on Amazon Web Services, Google Cloud, and Microsoft Foundry.
Sonnet 5 is available today at an introductory price of $2 per million input tokens and $10 per million output tokens through August 31, 2026, then moves to standard pricing at $3 per million input tokens and $15 per million output tokens, with up to 90% cost savings with prompt caching and 50% cost savings with batch processing. To learn more, check out our pricing page. To get started, simply use claude-sonnet-5 via the Claude API.
For workloads that need to run in the US, US-only inference is available at 1.1x pricing for input and output tokens. Learn more.
Use cases
Sonnet 5 is a powerful, versatile model built for daily use, scaled production, and complex tasks across coding, agents, and professional workflows.
API users have fine-grained control over the model’s thinking effort. Popular use cases include:
Advanced coding
Sonnet 5 delivers exceptional coding performance across the entire software development lifecycle. From initial planning and implementation to debugging, maintenance, and large-scale refactors, it excels at reasoning through complex, multi-file codebases, producing precise implementations, and iterating with minimal back-and-forth.
Long-running agents
Sonnet 5 offers superior instruction following, tool selection, and error correction for autonomous AI workflows. It reliably handles complex, multi-step tasks that require sustained coherence and adaptive decision-making, making it an ideal backbone for customer-facing agents, internal automation, and production-grade AI systems that need to operate independently at scale.
Browser and computer use
Sonnet 5 excels in computer use capabilities, reliably handling any browser-based task from competitive analysis to procurement workflows to customer onboarding. Building on the foundation that made Sonnet the first frontier AI model to use computers, Sonnet 5 navigates digital environments with greater accuracy and reliability, enabling enterprises to automate workflows that previously required human intervention.
Enterprise workflows
Sonnet 5 handles high-volume, high-stakes professional workflows across finance, research, content, and business operations. It can analyze complex financial data, synthesize insights from internal and external sources, generate and edit documents and spreadsheets, and produce compelling written content with nuance and precision.
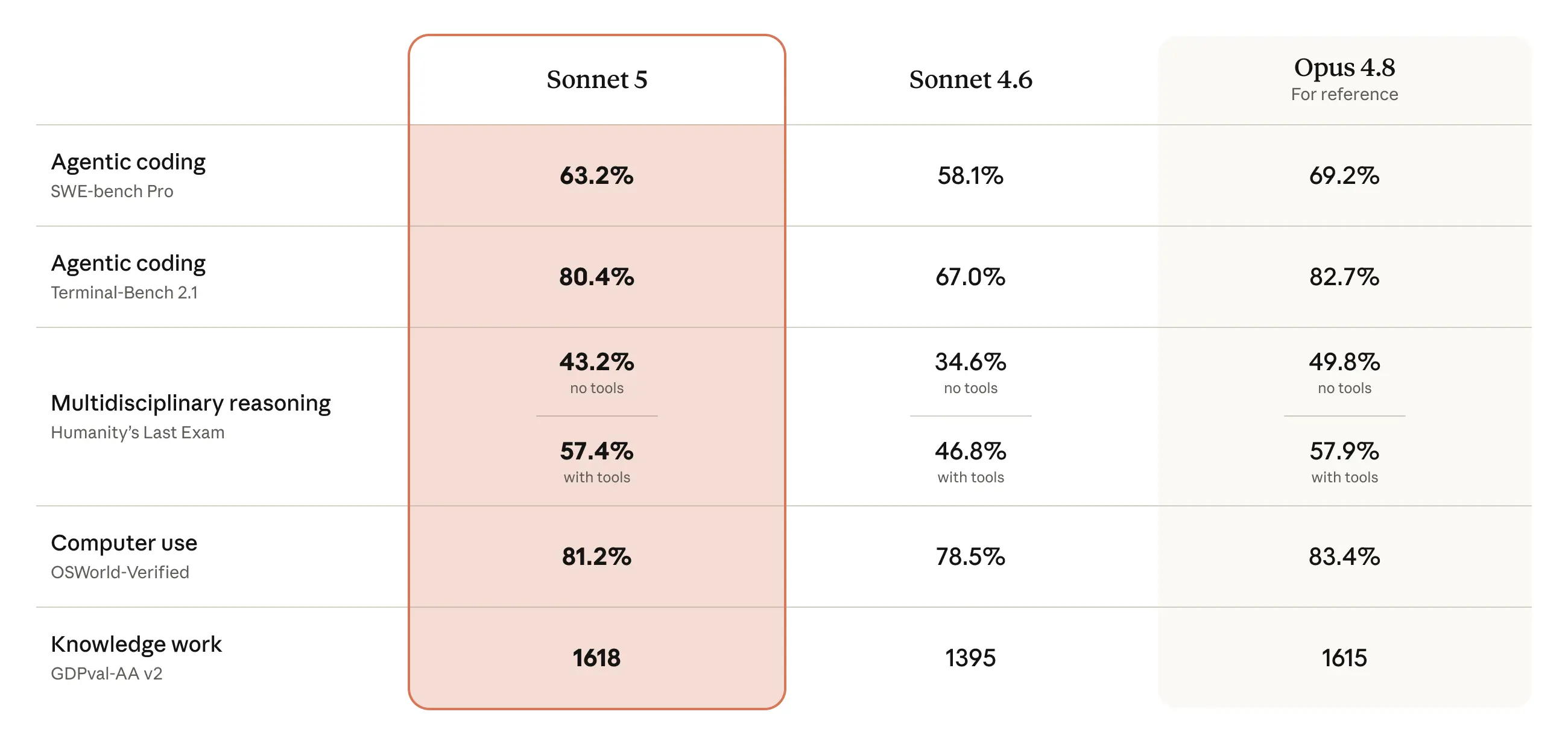
Benchmarks
Sonnet 5 delivers strong results across the benchmarks that matter most for real-world deployment, from reasoning and tool use to software coding, knowledge work, and more.
Trust & Safety
We’ve conducted extensive testing and evaluation of Sonnet 5, working with external experts to ensure it meets our standards for safety, security, and reliability. The accompanying system card covers safety results in depth.
Hear from our customers
Claude Sonnet 5 gives our agents a strong execution layer for multi-step software engineering work. It handles sustained coding, tool use, and debugging well across messy technical contexts, and has been especially useful for workflows where follow-through and technical grounding matter.
We handed Claude Sonnet 5 a two-part job—update Salesforce account tiers, send a launch announcement to enterprise contacts—and it finished end to end. That used to stall halfway. For day-to-day automation, it’s a no-brainer
Claude Sonnet 5 gets more done with less. Same output quality, fewer steps to get there. It refuses unsafe requests cleanly and consistently, too. At Lovable, we’re putting powerful tools in the hands of millions of builders. A model that knows when to say no is just as important as one that knows how to build.
We ran Claude Sonnet 5 against dozens of our most challenging real pull requests, and it carried each one through to a tested, verified result on its own — freeing our engineers to focus on the judgment, the decision, and the final sign-off.
I asked Claude Sonnet 5 to investigate a bug. Unprompted, it wrote a reproducing test, implemented the fix, then stashed it to confirm the bug came back without the change. All in a single pass.
With Claude Sonnet 5, agents stay on plan, follow our conventions, and ship clean multi-step changes, all at an efficient cost.
Claude Sonnet 5 is at its best on brownfield code—race conditions, hidden tests, the parts nobody wants to touch. It traces a failure to its actual root cause and ships a durable fix instead of patching the symptom.
Claude Sonnet 5 sits on the Pareto frontier for Eve’s plaintiff-law tasks. We see the clearest gains in legal research and analysis, at a price-to-performance ratio that made the choice to migrate easy.
ClickHouse agents explore live data and produce insights on the fly, so time-to-insight matters when testing new models. Claude Sonnet 5 reasons in tighter steps and gets our users to answers noticeably faster. That speed is a difference our customers feel.
At Pace, our computer-use agents run insurance workflows—submission intake, FNOL, loss runs—on the systems our operations teams already use. Claude Sonnet 5 consistently takes the right action and does it quickly, which is what real insurance work demands.
For enterprise teams managing high-volume, complex workloads, Claude Sonnet 5 represents a genuine step forward — strong performance where it counts, with the speed and cost profile that makes scaling practical. On several complex tasks it exceeds the current frontier, while delivering fast responses at low costs. For enterprises running at scale, that's a real operational win.
Claude Sonnet 5 handled the full range of coding tasks we tested it on, while resolving more issues. It's a meaningful improvement to both quality and efficiency.
Claude Sonnet 5 is a strong agentic-coding model, delivering top-tier accuracy comparable to Opus-class models and a clear step-function improvement over Sonnet 4.6. It conducts thorough explorations and sustains focus noticeably longer on complex tasks.
See Claude in action
Coding
What should I look for when reviewing a Pull Request for a Python web app?
Writing
Create a 3-month editorial calendar template for a weekly newsletter
Students
What’s an effective study schedule template for final exams?
Frequently asked questions
We offer different models across the spectrum of speed, price, and performance. Sonnet 5 delivers top-tier intelligence with optimal efficiency for high-volume use cases. We recommend Sonnet 5 for most AI applications where you need a balance of advanced capabilities and cost-efficient performance at scale. Common use cases include customer-facing agents, production coding workflows, content generation at scale, and real-time research tasks.
Pricing depends on how you want to use Sonnet 5. To learn more, check out our pricing page.