Claude Sonnet 4.6


Hybrid reasoning model with fast, capable intelligence for real-time agents and high-volume work, featuring a 1M context window
Announcements
- NEW
Claude Sonnet 4.6
Feb 17, 2026
Sonnet 4.6 delivers frontier performance across coding, agents, and professional work at scale. It can compress multi-day coding projects into hours and deliver production-ready solutions.
Read more
Claude Sonnet 4.5
Sep 29, 2025
Sonnet 4.5 is the best model in the world for agents, coding, and computer use. It’s also our most accurate and detailed model for long-running tasks, with enhanced domain knowledge in coding, finance, and cybersecurity.
Read more
Claude Sonnet 4
May 22, 2025
Sonnet 4 improves on Sonnet 3.7 across a variety of areas, especially coding. It offers frontier performance that’s practical for most AI use cases, including user-facing AI assistants and high-volume tasks.
Read more
Claude Sonnet 3.7 and Claude Code
Feb 24, 2025
Sonnet 3.7 is the first hybrid reasoning model and our most intelligent model to date. It’s state-of-the art for coding and delivers significant improvements in content generation, data analysis, and planning.
Read more
Availability and pricing
Anyone can chat with Claude using Sonnet 4.6 on Claude.ai, available on web, iOS, and Android.
For developers interested in building agents, Sonnet 4.6 is available on the Claude Platform natively, and in Amazon Bedrock, Google Cloud's Vertex AI, and Microsoft Foundry. The 1M token context window is currently available in beta on the API only.
Pricing for Sonnet 4.6 starts at $3 per million input tokens and $15 per million output tokens, with up to 90% cost savings with prompt caching and 50% cost savings with batch processing. To learn more, check out our pricing page. To get started, simply use claude-sonnet-4-6 via the Claude API.
Use cases
Sonnet 4.6 is a powerful, versatile model built for daily use, scaled production, and complex tasks across coding, agents, and professional workflows.
Sonnet 4.6 can produce near-instant responses or extended, step-by-step thinking. API users also have fine-grained control over the model's thinking effort. Popular use cases include:
Advanced coding
Sonnet 4.6 delivers exceptional coding performance across the entire software development lifecycle. From initial planning and implementation to debugging, maintenance, and large-scale refactors, it excels at reasoning through complex, multi-file codebases, producing precise implementations, and iterating with minimal back-and-forth.
Long-running agents
Sonnet 4.6 offers superior instruction following, tool selection, and error correction for autonomous AI workflows. It reliably handles complex, multi-step tasks that require sustained coherence and adaptive decision-making, making it an ideal backbone for customer-facing agents, internal automation, and production-grade AI systems that need to operate independently at scale.
Browser and computer use
Sonnet 4.6 excels in computer use capabilities, reliably handling any browser-based task from competitive analysis to procurement workflows to customer onboarding. Building on the foundation that made Sonnet the first frontier AI model to use computers, Sonnet 4.6 navigates digital environments with greater accuracy and reliability, enabling enterprises to automate workflows that previously required human intervention.
Enterprise workflows
Sonnet 4.6 handles high-volume, high-stakes professional workflows across finance, research, content, and business operations. It can analyze complex financial data, synthesize insights from internal and external sources, generate and edit documents and spreadsheets, and produce compelling written content with nuance and precision.
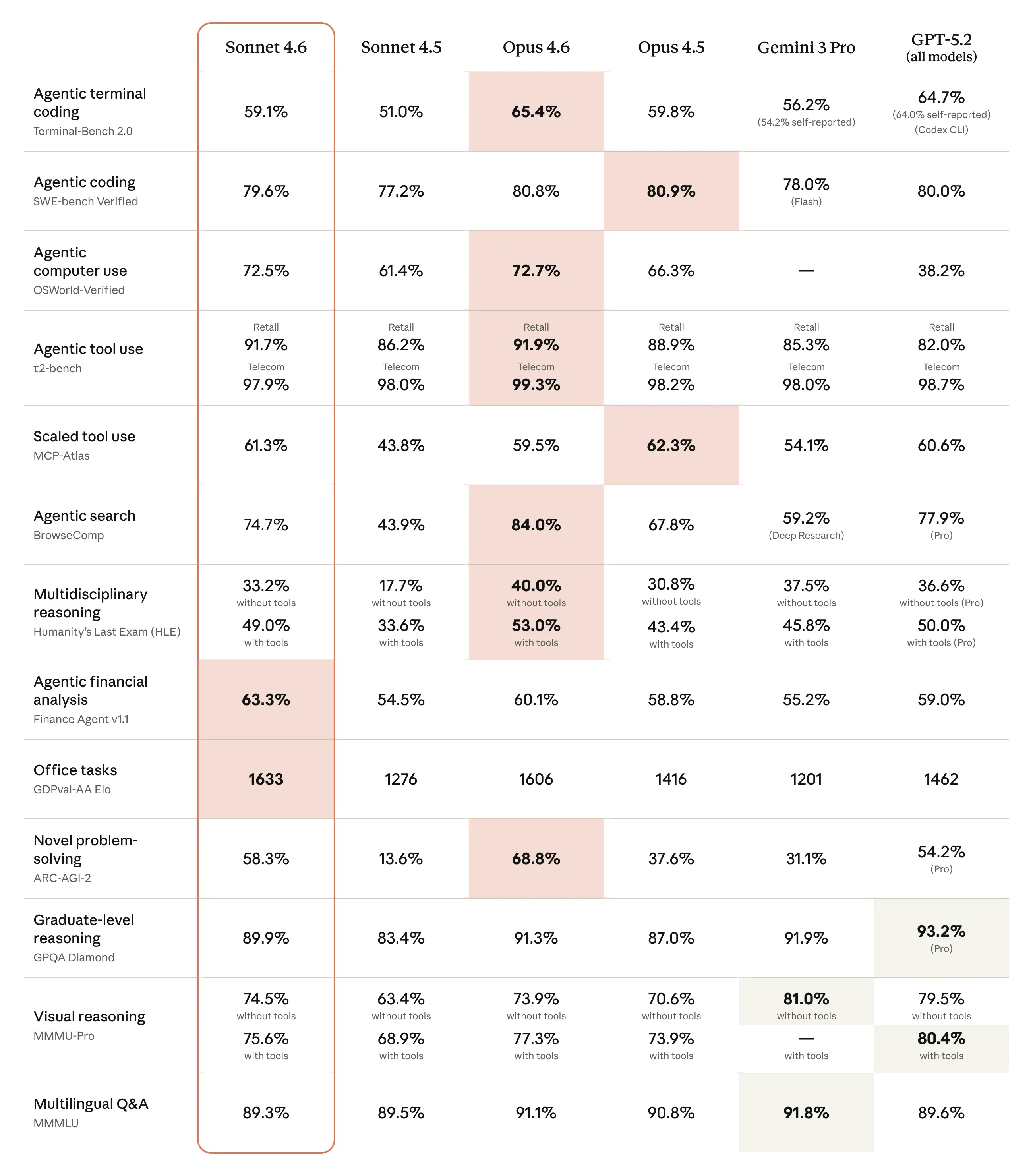
Benchmarks
Sonnet 4.6 delivers strong results across the benchmarks that matter most for real-world deployment, from agentic coding and tool use to complex reasoning and long-context tasks.
Trust & Safety
We’ve conducted extensive testing and evaluation of Sonnet 4.6, working with external experts to ensure it meets our standards for safety, security, and reliability. The accompanying model card covers safety results in depth.
Hear from our customers
Out of the gate, Claude Sonnet 4.6 is already excelling at complex code fixes, especially when searching across large codebases is essential. For teams running agentic coding at scale, we're seeing strong resolution rates and the kind of consistency developers need.
Claude Sonnet 4.6 produced the best iOS code we've tested for Rakuten AI. Better spec compliance, better architecture, and it reached for modern tooling we didn't ask for, all in one shot. The results genuinely surprised us.
The performance-to-cost ratio of Claude Sonnet 4.6 is extraordinary — it’s hard to overstate how fast Claude models have been evolving in recent months. Sonnet 4.6 outperforms on our orchestration evals, handles our most complex agentic workloads, and keeps improving the higher you push the effort settings.
Claude Sonnet 4.6 is noticeably more capable on the hard problems where Sonnet 4.5 falls short, and shows strength on tasks that normally require the autonomy and agentic capabilities of an Opus model.
Claude Sonnet 4.6 punches way above its weight class for the vast majority of real-world PRs, and even improving more than 10 points on the hardest bug finding problems over Sonnet 4.5. For the code that actually ships, it's become our default.
On our long-horizon coding eval — where every feature builds on the last and you live with your earlier decisions — Sonnet 4.6 matches Opus 4.5. Fewer tokens. Faster. For most engineering, start here.
Claude Sonnet 4.6 has perfect design taste when building frontend pages and data reports, and it requires far less hand-holding to get there than anything we've tested before.
Claude Sonnet 4.6 is faster, cheaper, and more likely to nail things on the first try. That was a surprising set of improvements, and we didn't expect to see it at this price point.
Claude Sonnet 4.6 benchmarks near Opus-level on the coding tasks we care about, with meaningfully better instruction-following and tool reliability than its predecessor. We’re transitioning our Sonnet traffic over to this model.
Claude Sonnet 4.6 meaningfully improves the answer retrieval behind our core product — we saw a significant jump in answer match rate, compared to Sonnet 4.5, in our Financial Services Benchmark, with better recall on the specific workflows our customers depend on.
Claude Sonnet 4.6 rivals the best models on UI layout and leaps past the previous Sonnet. It's the model we want building apps for our users.
We're moving the majority of our traffic to Claude Sonnet 4.6. With adaptive thinking and high effort, we see Opus-level performance on all but our hardest analytical tasks with a more efficient and flexible profile. At Sonnet pricing, it's an easy call for our workloads.
Claude Sonnet 4.6 hit 94% on our complex insurance computer use benchmark, the highest of any Claude model we tested. It reasons through failures and self-corrects in ways we haven't seen before.
Box evaluated how Claude Sonnet 4.6 performs when tested on deep reasoning and complex agentic tasks across real enterprise documents. It demonstrated significant improvements, outperforming Claude Sonnet 4.5 in heavy reasoning Q&A by 15 percentage points.
Claude Sonnet 4.6 delivers frontier-level results on complex app builds and bugfixing. It's becoming our go-to for the kind of deep codebase work that used to require more expensive models.
Claude Sonnet 4.6's consistency across complex multi-character stories is genuinely impressive — it keeps each character's voice distinct in ways that make our narratives feel more alive.
We’ve been impressed by how accurately Claude Sonnet 4.6 handles complex computer use. It’s a clear improvement over anything else we’ve tested in our evals.
Claude Sonnet 4.6 excels at the behaviors that matter most for real knowledge work, scoring high in our internal evals, while making fewer tool calls and hitting fewer tool errors. The result is an AI that handles complicated, multi-step requests more reliably and produces more consistent, polished work.
Claude Sonnet 4.6 matches Opus 4.6 performance on OfficeQA, which measures how well a model can read enterprise documents (charts, PDFs, tables), pull the right facts, and reason from those facts. It's a meaningful upgrade for document comprehension workloads.
Claude Sonnet 4.6 achieves speed, quality, and economy. We especially like the 1M token context for larger projects. It surprises with intuitive and thoughtful comments, pushing back thoughtfully and genuinely understanding the goals of its work.
Claude Sonnet 4.6 is a notable improvement over Sonnet 4.5 across the board, including long horizon tasks and more difficult problems.
Claude Sonnet 4.6 has meaningfully closed the gap with Opus on bug detection, letting us run more reviewers in parallel, catch a wider variety of bugs, and do it all without increasing cost.
For the first time, Claude Sonnet 4.6 brings frontier-level reasoning in a smaller and more cost effective form factor. It provides a viable alternative if you are a heavy Opus user.
Claude Sonnet 4.6 is a significant leap forward on reasoning through difficult tasks. We find it especially strong on branched and multi-step tasks like contract routing, conditional template selection, and CRM coordination — exactly where our customers need strong model sense and reliability.
In Rovo Dev testing, Claude Sonnet 4.6 proved to be a highly effective main agent, leveraging subagents to sustain longer-running tasks.
Claude Sonnet 4.6 shows impressive progress in reasoning, code understanding, and memory—key ingredients for agentic automation. Our early tests integrating it into Postman Agent Mode point to smoother, more capable end-to-end workflows, and we’re excited about what this means for API developers building with automation at scale.
Claude Sonnet 4.6 was exceptionally responsive to direction — delivering precise figures and structured comparisons when asked, while also generating genuinely useful ideas on trial strategy and exhibit preparation.
In our zero-shot app building experiments, Sonnet 4.6 ran up to 3-4x longer without intervention, producing functional apps on par with the Opus series.
Claude Sonnet 4.6 produced zero hallucinated links in our computer use evals. Previously, we saw about one in three hallucinated links. That kind of reliability is what actually makes browser automation deployable at scale.
On our filesystem benchmark, Claude Sonnet 4.6 is 70% more token-efficient than Sonnet 4.5 model with a 38% accuracy improvement. That changes the economics of what we can build.
See Claude in action
Coding
What should I look for when reviewing a Pull Request for a Python web app?
Writing
Create a 3-month editorial calendar template for a weekly newsletter
Students
What's an effective study schedule template for final exams?
Frequently asked questions
We offer different models across the spectrum of speed, price, and performance. Sonnet 4.6 delivers superior intelligence with optimal efficiency for high-volume use cases. We recommend Sonnet 4.6 for most AI applications where you need a balance of advanced capabilities and cost-efficient performance at scale. Common use cases include customer-facing agents, production coding workflows, content generation at scale, and real-time research tasks.
Pricing depends on how you want to use Sonnet 4.6. To learn more, check out our pricing page.
Sonnet 4.6 is both a standard model and a hybrid reasoning model in one: you can pick when you want the model to answer normally and when you want it to use extended thinking.
Extended thinking mode is best when performance and accuracy matter more than latency. It significantly improves response quality for complex reasoning tasks, extended agentic work, multi-step coding projects, and deep research. Thinking summaries help you understand key aspects of the model's reasoning process.