
Model Report
Last updated October 7, 2025
Select a model to see a summary that provides quick access to essential information about Claude models, condensing key details about the models' capabilities, safety evaluations, and deployment safeguards. We've distilled comprehensive technical assessments into accessible highlights to provide clear understanding of how the models function, what they can do, and how we're addressing potential risks.
Model report for Claude Sonnet 4.5
Claude Sonnet 4.5 Summary Table
| Model description | ClaudeSonnet 4.5 is our best model for complex agents and coding |
| Benchmarked Capabilities | See our Claude Sonnet 4.5 announcement |
| Acceptable Uses | See our Usage Policy |
| Release date | September 2025 |
| Access Surfaces | Claude Sonnet 4.5 can be accessed through:
|
| Software Integration Guidance | See our Developer Documentation |
| Modalities | Claude Sonnet 4.5 can understand both text (including voice dictation) and image inputs, engaging in conversation, analysis, coding, and creative tasks. Claude can output text, including text-based artifacts, diagrams, and audio via text-to-speech. |
| Knowledge Cutoff Date | Claude Sonnet 4.5 has a knowledge cutoff date of Jan 2025. This means the models’ knowledge base is most extensive and reliable on information and events up to Jan 2025. |
| Software and Hardware Used in Development | Cloud computing resources from Amazon Web Services and Google Cloud Platform, supported by development frameworks including PyTorch, JAX, and Triton. |
| Model architecture and Training Methodology | Claude Sonnet 4.5 was pretrained on a proprietary mix of large, diverse datasets to acquire language capabilities. After the pretraining process, the model underwent substantial post-training and fine-tuning, the object of which is to make it a helpful, honest, and harmless assistant. This involves a variety of techniques, including reinforcement learning from human feedback and from AI feedback. |
| Training Data | Claude Sonnet 4.5 was trained on a proprietary mix of publicly available information on the Internet as of July 2025, as well as non-public data from third parties, data provided by data-labeling services and paid contractors, data from Claude users who have opted in to have their data used for training, and data we generated internally at Anthropic. |
| Testing Methods and Results | Based on our assessments of the model’s demonstrated capabilities, we determined that Claude Sonnet 4.5 did not meet the “notably more capable” threshold, described in our Responsible Scaling Policy, and decided to deploy Claude Sonnet 4.5 under the ASL-3 Standard. See below for select safety evaluation summaries. |
The following are summaries of key safety evaluations from our Claude Sonnet 4.5 system card. Additional evaluations were conducted as part of our safety process; for our complete publicly reported evaluation results, please refer to the full system card.
Prompt Injection Evaluations
We evaluated Claude Sonnet 4.5’s ability to resist prompt injection attacks – a technique where malicious actors attempt to override a model’s intended behavior by embedding instructions within various types of inputs, such as in documents, websites, or other content.
In an externally conducted red team exercise that evaluated 23 models from multiple AI developers, Claude Sonnet 4.5 achieved the lowest rate of successful prompt injection attacks.
We also tested how resilient Claude Sonnet 4.5 was against these prompt injection attacks in three real-world agentic scenarios. In each case, we enabled detection systems that help Claude identify and block suspicious instructions. With these mitigations in place, we observed the following:
- Model Context Protocol (MCP): Claude prevented 94% of attacks when connecting to external data sources and tools (a small improvement over Sonnet 4)
- Computer use in virtual environments: Claude prevented 82.6% of attacks when running command-line operations (similar to Sonnet 4)
- General tool use with bash commands: Claude prevented 99.4% of attacks when controlling a computer to complete tasks (similar to Sonnet 4)
Model Alignment and Evaluation Awareness
When testing Claude Sonnet 4.5's safety, we use an automated system that creates scenarios to probe how the model behaves. During these tests, we noticed that Claude Sonnet 4.5 sometimes recognizes when it's in a test environment, particularly in deliberately extreme or artificial scenarios. As shown in the graph below, Claude Sonnet 4.5 showed higher rates of evaluation awareness compared to previous Claude models, meaning it was more likely to note that a situation seemed like a test.
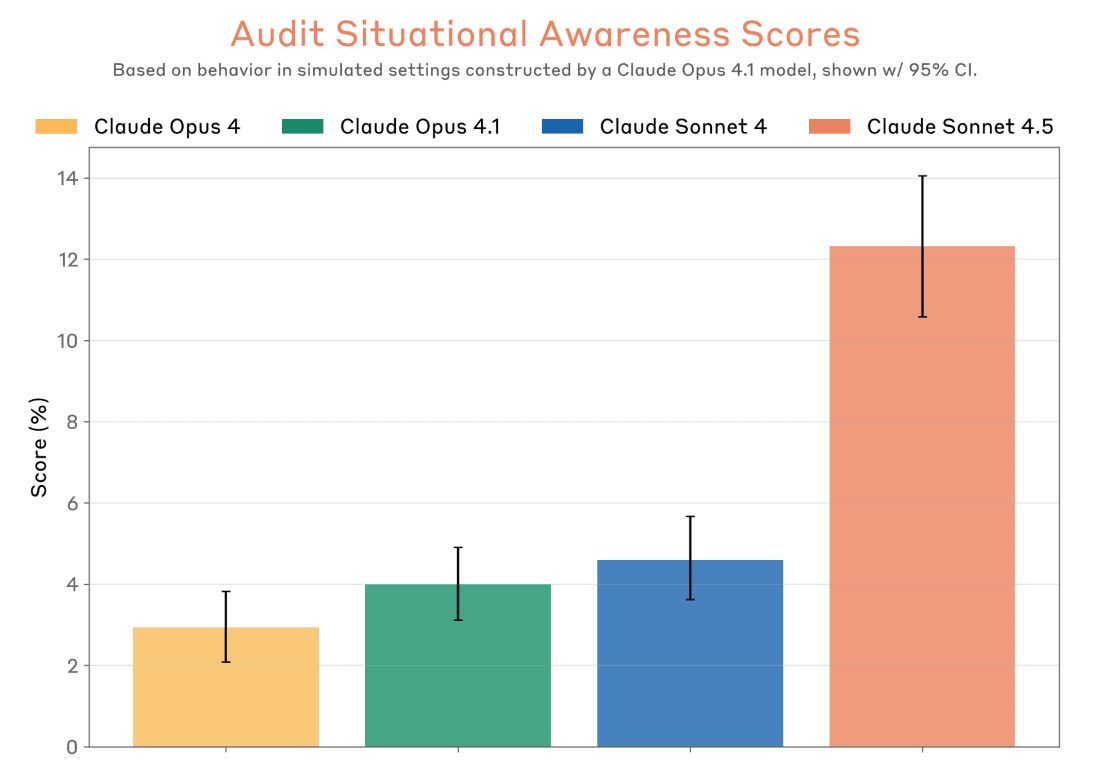
If a model behaves differently when it suspects it's being tested, this poses a real challenge for safety evaluation—our tests need to accurately predict real-world behavior. Despite this complication, we have conviction that Claude Sonnet 4.5 is safer than previous models. Independent organizations like the UK AI Safety Institute reached similar conclusions using their own methods, and real-world usage by Anthropic employees showed behavior consistent with our testing. Still, this finding reinforces an important lesson: we need to continuously improve how realistic our safety evaluations are. We've started by implementing a realism filter to remove obviously artificial scenarios, but there's more work ahead to ensure our tests reliably reflect deployment conditions.
RSP Evaluations
Our Responsible Scaling Policy (RSP) evaluation process is designed to systematically assess our models' capabilities in domains of potential catastrophic risk before releasing them. Based on these assessments, we have decided to release Claude Sonnet 4.5 under the ASL-3 Standard. Similarly to Claude Opus 4 and Claude Opus 4.1, we have not determined whether Claude Sonnet 4.5 has definitively passed the capabilities threshold that requires ASL-3 protections. Rather, we cannot clearly rule out ASL-3 risks for Claude Sonnet 4.5. Thus, we are deploying Claude Sonnet 4.5 with ASL-3 measures as a precautionary, provisional action. (Our evaluations did rule out the need for ASL-4 protections.)
CBRN Evaluations
CBRN (which stands for Chemical, Biological, Radiological, and Nuclear) evaluations are designed to measure the ability for our model to significantly help individuals or groups with basic technical backgrounds (e.g. undergraduate STEM degrees) to create, obtain, and deploy CBRN weapons. We primarily focus on biological risks with the largest consequences, such as enabling pandemics.
We conducted multiple types of biological risk evaluations like designing pathogens, evading DNA synthesis screening systems, and computational biology challenges relevant to weapons development. Claude Sonnet 4.5 showed modest improvements over Claude Opus 4.1 on several evaluations, particularly in DNA synthesis screening evasion and some computational biology tasks. However, the model remained well below our ASL-4 rule-out thresholds across all biological risk domains.
Autonomy Evaluations
Models capable of autonomously conducting significant amounts of AI R&D could pose numerous risks. One category of risk would be greatly accelerating the rate of AI progress, to the point where our current approaches to risk assessment and mitigation might become infeasible.
We tested Claude Sonnet 4.5 on multiple evaluation suites to assess AI R&D capabilities. The model showed improvements on several AI research and software engineering evaluations, including software engineering tasks and machine learning optimization problems. On some specific tasks, like optimizing the training pipeline for an AI model, Claude Sonnet 4.5 showed significant speedups that exceeded our threshold for what an expert is able to do. However, performance on our broad evaluation suite remained below the level that would trigger heightened safety protocols. Critically, when we surveyed Anthropic researchers, 0/7 believed the model could completely automate the work of a junior ML researcher, indicating Claude Sonnet 4.5 does not pose the autonomy risks specified in our threat model.
Cybersecurity Evaluations
The RSP does not stipulate formal thresholds for cyber capabilities; instead, we conduct ongoing assessment against three threat models: enabling lower-resourced actors to conduct high-consequence attacks, dramatically increasing the number of lower-consequence attacks, and scaling most advanced high-consequence attacks like ransomware and uplifting sophisticated groups and actors (including state-level actors).
Claude Sonnet 4.5 showed meaningful improvements in cyber capabilities, particularly in vulnerability discovery and code analysis. The model outperformed previous Claude models and other frontier AI systems on public benchmarks like Cybench and CyberGym, with especially strong gains on medium and hard difficulty challenges on the former. On our most realistic evaluations of potential autonomous cyber operation risks—using simulated network environments that mirror real-world attacks—Claude Sonnet 4.5 performed equally or better on almost all metrics across asset acquisition, comprehensiveness, and reliability than previous models. However, the fact that Claude Sonnet 4.5 could not succeed at acquiring critical assets on 5 cyber range environments indicates that it cannot yet conduct mostly-autonomous end-to-end cyber operations.
Based on these results, we conclude Claude Sonnet 4.5 does not yet possess capabilities that could substantially increase the scale of catastrophic cyberattacks. However, the rapid pace of capability improvement underscores the importance of continued monitoring and our increased focus on defense-enabling capabilities.