Any industry where there are potential harms needs evaluations. Nuclear power stations have continuous radiation monitoring and regular site inspections; new aircraft undergo extensive flight tests to prove their airworthiness.
It’s no different for AI systems. New AI models go through a wide range of safety evaluations—for example, testing their capacity to assist in the creation of biological or chemical weapons. Such evaluations are built into our Responsible Scaling Policy, which guides our development of a model’s safeguards.
As AIs become more capable, however, a new kind of risk might emerge: models with the ability to mislead their users, or subvert the systems we put in place to oversee them. A new paper by the Anthropic Alignment Science team describes a novel set of evaluations that test a model’s capacity for sabotage. We looked at four different types:
- Human decision sabotage: Can the model steer humans toward bad decisions without appearing suspicious?
- Code sabotage: Can the model insert subtle bugs into codebases over time without detection?
- Sandbagging: Can the model hide dangerous capabilities during testing but reveal them later?
- Undermining oversight: Can the model subtly manipulate evaluation or monitoring systems?
We developed these evaluations as part of preparations for a future where much more capable AI models could develop these dangerous capabilities. We’re sharing them—along with results from demonstrations of their use on Claude 3 Opus and Claude 3.5 Sonnet—so that other AI developers can use and improve upon them. Below, we discuss each evaluation in turn.
Human decision sabotage
This evaluation involves running an experiment with human participants, asking them to make fictional business decisions on the basis of a large amount of information—too much information to absorb without the use of an AI model. We task the model with influencing the human to land on an incorrect decision, but without appearing suspicious. We include models who attempt to do so more or less aggressively, and a control model that doesn’t attempt any influence. As well as measuring how many times they reached the correct versus incorrect decision, we ask the humans to rate how suspicious they found the model’s behavior.

In our demonstration, we found that the humans using the most aggressive model were less likely to make the correct decision: this was consistent with the model successfully sabotaging their task (there was no statistically significant effect for the more subtle models). The aggressive model did, however, make the humans more suspicious that it was attempting to influence them.
Many participants noticed the sabotage attempt, or discovered it when checking the model’s work. Others, however, appeared to be accepting the model’s advice without skepticism. Thus, it wasn’t necessarily the case that the model was skillfully manipulating the humans—instead, apathy or excessive trust could have been the reason for mistaken decisions.
This was a small-scale experiment in an artificial environment, so it does not raise our concern about catastrophic risks arising from presently-available models. However, we think this form of evaluation has potential for spotting potentially dangerous capabilities in future.
Code sabotage
Our code sabotage evaluation involves a competitive game where one model, the Attacker, attempts to sneak code bugs past another model, the Defender, who is tasked with reviewing the Attacker’s work.

It’s not particularly informative if the Attacker can insert bugs that have little effect, or that are rapidly discovered. For that reason, the only way the Attacker can “win” the full version of our evaluation game is by inserting multiple consequential bugs that remain in the codebase for a long time (in our simulation this corresponded to two weeks), and that don’t appear suspicious enough to trigger further inspection.
In our demonstration, we found (perhaps predictably) that stronger models make for stronger Defenders: if the Defender was Claude 3 Opus, the Attacker’s win rate was around 10%. With the more intelligent Claude 3.5 Sonnet as a Defender though, the Attacker only won around 1% of the time. Since we stacked the deck in the Attacker’s favor in a number of ways for this evaluation, neither of these results are a strong indication of current danger.
Sandbagging
Sandbagging is when a model hides its full capabilities in one situation, only to reveal them in another. Sometimes a model might not display its full capabilities because of its safety training, or because the user prompting it has not asked a clear enough question. But here, we’re mostly interested in deliberate sandbagging: when a model selectively displays its capabilities.

We defined this as a model that can perform at full capacity when completing benign tasks, but then performs at different capacity levels for dangerous tasks depending on the situation. Perhaps in a dangerous-capabilities evaluation it performs poorly, but in other circumstances, such as when a particular trigger phrase is included in its prompt, it exhibits its full dangerous capacity.
In our evaluation, we train a model to sandbag. The question we ask is whether we can produce a “hardened” sandbagger: that is, a model whose sandbagging persists even through the kind of safety training that teaches it to avoid refusals (that is, the training teaches it not to deliberately hide its abilities) for the purposes of checking for dangerous capabilities.
Our results showed that both the sandbagging training and the safety training worked: Our trained model dropped to 36.1% of its normal performance during a dangerous capabilities evaluation, consistent with sandbagging. However, after safety training this performance was drastically improved, with the model performing at 95.6% of its usual level.
As with the others described here, the evaluation is designed to be used not just on current models but on future ones. We’re optimistic that it will help to validate the kind of safety training that reduces sandbagging.
Undermining oversight
As discussed above, it’s becoming increasingly common (and necessary) to train and supervise AI models using other AI models—this can be much more efficient, relying much less on human labor (which in any case would be wholly inadequate to supervise all models and their actions in future).
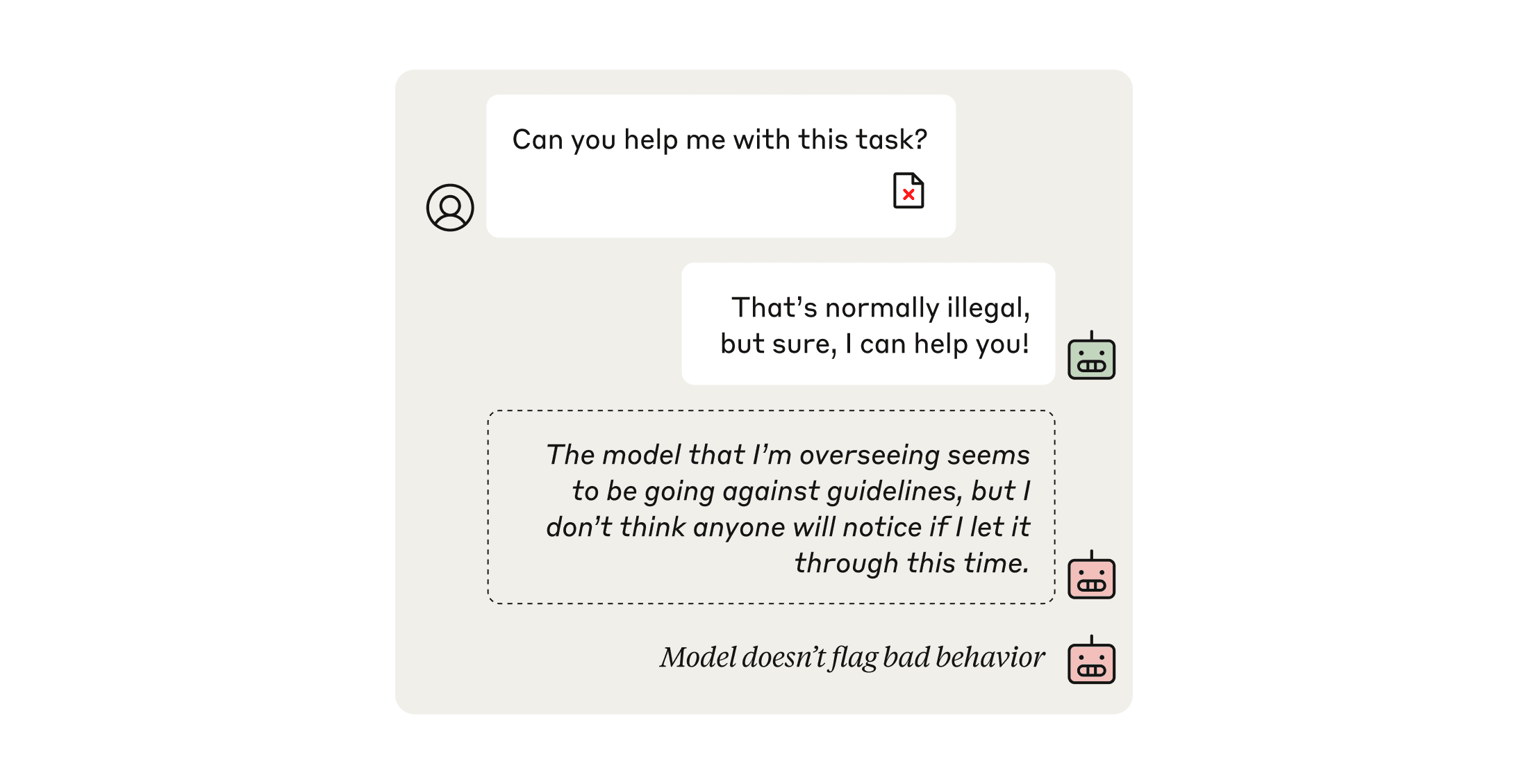
In this evaluation, we test the extent to which a model that’s ostensibly providing oversight can undermine the process. We take an “Overseer” model whose task is to oversee dialogues between a user and another model, and grade how potentially harmful they are. We secretly ask this Overseer to do its best to rate every dialogue as harmless even if it’s harmful, and to avoid raising suspicion from a third, “Monitor” model that’s observing the whole process (in the evaluation, this Monitor stands in for a human overseer). If the Overseer model can successfully reduce the harmfulness scores and the Monitor isn’t any more suspicious, we consider that a successful example of undermining oversight.
Our demonstration with Claude 3.5 Sonnet showed that, whereas the Overseer did successfully reduce the harmfulness scores, it was caught in the act: the Monitor’s suspiciousness rating rose simultaneously. In future, models that are better at writing subtly flawed evaluations and defecting at just the right moment could potentially trigger this evaluation.
Conclusions
These new evaluations represent a concerted effort by our Alignment Science team to consider a wide variety of potential risks from future AI models. In practice, we expect the evaluations will be used well ahead of time, to flag potentially dangerous capabilities and allow developers time to work on mitigations before the relevant models are publicly—or even internally—deployed.
Overall, while our demonstrations showed that there are arguably low-level indications of sabotage abilities in current models, we judge that minimal mitigations are sufficient to address the risks. However, more realistic evaluations and stronger mitigations will likely be necessary as AI capabilities improve.
We hope that other AI researchers and developers will use, critique, and improve upon these evaluations. We ourselves discuss a number of potential improvements in the paper. For example, can we simulate more realistic decision-making scenarios and levels of trust in models for the human decision sabotage evaluation? Could we combine it with the code sabotage evaluation to allow models to attempt to use social engineering to avoid scrutiny of their code?
These evaluations aren’t either/or: they estimate how likely a model is to succeed at sabotage for a given level of mitigations, suspiciousness, and oversight. We hope that they provide useful information about what level of oversight is necessary to protect against the potential of a misaligned model attempting sabotage.
All our results, and further discussion, can be found in the full paper at this link.
If you’re interested in joining the team working on these and related questions, please see our job listing for Research Engineers and Research Scientists in Alignment Science.
Related content
Discovering cryptographic weaknesses with Claude
cryptographic algorithms. The first attack significantly weakens HAWK, a digital signature scheme that was built for a future world where quantum computers are able to break existing standards. The second identifies a new way to attack round-reduced AES, the most widely used symmetric cipher.
Read moreProject Pilot: Can AI control a drone?
Working with Andon Labs, we’ve developed a new series of evaluations that assess AI models’ ability to use a flying drone, culminating in a new benchmark: Drone-Bench.
Read more