Claude Opus 4.5


Hybrid reasoning model that pushes the frontier for coding and AI agents, featuring a 200K context window
Announcements
- NEW
Claude Opus 4.5
Nov 24, 2025
Claude Opus 4.5 is our most intelligent model to date. It sets a new standard across coding, agents, computer use, and enterprise workflows. Opus 4.5 is a meaningful step forward in what AI systems can do.
Read more
Claude Opus 4.1
Aug 5, 2025
Claude Opus 4.1 is a drop-in replacement for Opus 4 that delivers superior performance and precision for real-world coding and agentic tasks. It handles complex, multi-step problems with more rigor and attention to detail.
Read more
Claude Opus 4
May 22, 2025
Claude Opus 4 pushes the frontier in coding, agentic search, and creative writing. We’ve also made it possible to run Claude Code in the background, enabling developers to assign long-running coding tasks for Opus to handle independently.
Read more
Availability and pricing
For business users and consumers who want to collaborate with our most powerful model on complex tasks, Opus 4.5 is available on Claude for Pro, Max, Team, and Enterprise users.
For developers interested in building AI solutions that demand frontier intelligence, Opus 4.5 is available on the Claude Developer Platform natively, and in Amazon Bedrock, Google Cloud’s Vertex AI, and Microsoft Foundry.
Pricing for Opus 4.5 starts at $5 per million input tokens and $25 per million output tokens, with up to 90% cost savings with prompt caching and 50% savings with batch processing. To learn more, check out our pricing page. To get started, use claude-opus-4-5 via the Claude API.
Use cases
Opus 4.5 is a premium model that works best for use cases no prior model has solved before and where performance matters most. It’s built for professional software engineering, complex agentic workflows, and high-stakes enterprise tasks.
Opus 4.5 offers hybrid reasoning that allows for instant responses or extended thinking. API users have fine-grained controls for adjusting the overall effort it puts into a response, balancing performance with latency and cost. Popular use cases include:
Advanced coding
Opus 4.5 can confidently deliver multi-day software development projects in hours, working independently with the technical depth and taste to create efficient and straightforward solutions. It has improved performance across coding languages, with better planning and architecture choices—making it the ideal model for enterprise developers. In our own testing, it’s even able to pass our most challenging coding interviews.
AI agents
Opus 4.5, paired with our next wave of tool use improvements, enables more capable agents with new behaviors. It excels at complex, multi-step tasks that require sustained reasoning and adaptive decision-making—ideal for agentic workflows where reliability and autonomy matter most.
Enterprise workflows
Opus 4.5 can power agents that manage sprawling professional projects from start to finish. It better leverages memory to maintain context and consistency across files, alongside a step-change improvement in creating spreadsheets, slides, and docs. It delivers the sustained quality that ongoing enterprise projects demand.
Benchmarks
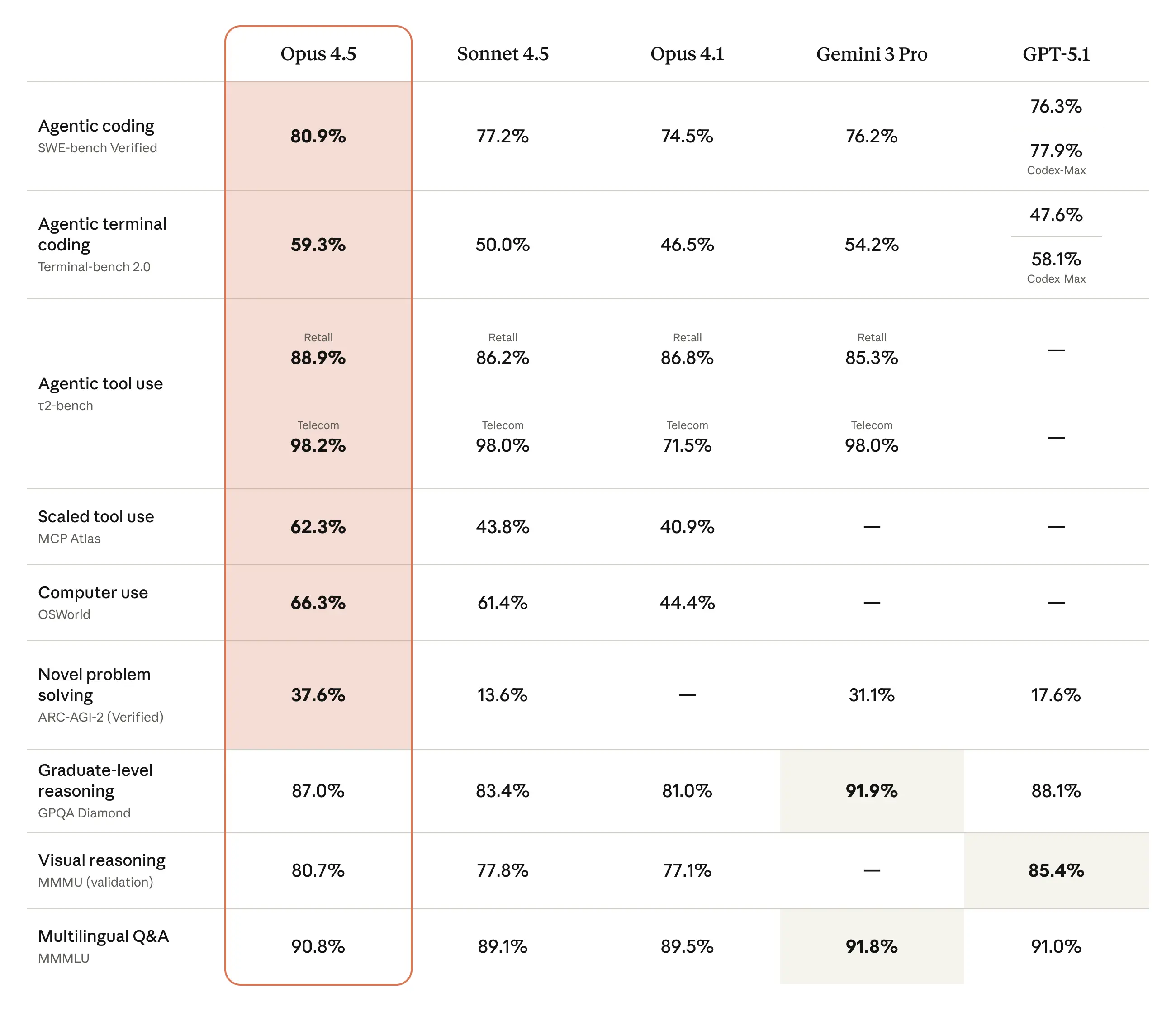
Claude Opus 4.5 is state-of-the-art on tests of real-world software coding and agentic capabilities.
Opus 4.5 demonstrates strong performance across many domains. It achieves industry-leading results with 80.9% on SWE-bench Verified. It is also our best computer-using model, reaching 66.3% on OSWorld.
Trust and safety
Extensive testing and evaluation—conducted in partnership with external experts—ensures the release of Opus 4.5 meets Anthropic’s standards for safety, security, and reliability. The accompanying model card covers safety results in depth.
Hear from our customers
Opus models have always been “the real SOTA” but have been cost prohibitive in the past. Claude Opus 4.5 is now at a price point where it can be your go-to model for most tasks. It’s the clear winner and exhibits the best frontier task planning and tool calling we’ve seen yet.
Claude Opus 4.5 delivers high-quality code and excels at powering heavy-duty agentic workflows with GitHub Copilot. Early testing shows it surpasses internal coding benchmarks while cutting token usage in half, and is especially well-suited for tasks like code migration and code refactoring.
Claude Opus 4.5 beats Sonnet 4.5 and competition on our internal benchmarks, using fewer tokens to solve the same problems. At scale, that efficiency compounds.
Claude Opus 4.5 delivers frontier reasoning within Lovable's chat mode, where users plan and iterate on projects. Its reasoning depth transforms planning—and great planning makes code generation even better.
Claude Opus 4.5 excels at long-horizon, autonomous tasks, especially those that require sustained reasoning and multi-step execution. In our evaluations it handled complex workflows with fewer dead-ends. On Terminal Bench it delivered a 15% improvement over Sonnet 4.5, a meaningful gain that becomes especially clear when using Warp’s Planning Mode.
Claude Opus 4.5 achieved state-of-the-art results for complex enterprise tasks on our benchmarks, outperforming previous models on multi-step reasoning tasks that combine information retrieval, tool use, and deep analysis.
Claude Opus 4.5 delivers measurable gains where it matters most: stronger results on our hardest evaluations and consistent performance through 30-minute autonomous coding sessions.
Claude Opus 4.5 represents a breakthrough in self-improving AI agents. For office automation, our agents were able to autonomously refine their own capabilities—achieving peak performance in 4 iterations while other models couldn’t match that quality after 10.
Claude Opus 4.5 is a notable improvement over the prior Claude models inside Cursor, with improved pricing and intelligence on difficult coding tasks.
Claude Opus 4.5 is yet another example of Anthropic pushing the frontier of general intelligence. It performs exceedingly well across difficult coding tasks, showcasing long-term goal-directed behavior.
Claude Opus 4.5 delivered an impressive refactor spanning two codebases and three coordinated agents. It was very thorough, helping develop a robust plan, handling the details and fixing tests. A clear step forward from Sonnet 4.5.
Claude Opus 4.5 handles long-horizon coding tasks more efficiently than any model we’ve tested. It achieves higher pass rates on held-out tests while using up to 65% fewer tokens, giving developers real cost control without sacrificing quality.
We’ve found that Opus 4.5 excels at interpreting what users actually want, producing shareable content on the first try. Combined with its speed, token efficiency, and surprisingly low cost, it’s the first time we’re making Opus available in Notion Agent.
Claude Opus 4.5 excels at long-context storytelling, generating 10-15 page chapters with strong organization and consistency. It's unlocked use cases we couldn't reliably deliver before.
Claude Opus 4.5 sets a new standard for Excel automation and financial modeling. Accuracy on our internal evals improved 20%, efficiency rose 15%, and complex tasks that once seemed out of reach became achievable.
Claude Opus 4.5 is the only model that nails some of our hardest 3D visualizations. Polished design, tasteful UX, and excellent planning & orchestration - all with more efficient token usage. Tasks that took previous models 2 hours now take thirty minutes.
Claude Opus 4.5 catches more issues in code reviews without sacrificing precision. For production code review at scale, that reliability matters.
Based on testing with Junie, our coding agent, Claude Opus 4.5 outperforms Sonnet 4.5 across all benchmarks. It requires fewer steps to solve tasks and uses fewer tokens as a result. This indicates that the new model is more precise and follows instructions more effectively — a direction we’re very excited about.
The effort parameter is brilliant. Claude Opus 4.5 feels dynamic rather than overthinking, and at lower effort delivers the same quality we need while being dramatically more efficient. That control is exactly what our SQL workflows demand.
We’re seeing 50% to 75% reductions in both tool calling errors and build/lint errors with Claude Opus 4.5. It consistently finishes complex tasks in fewer iterations with more reliable execution.
Claude Opus 4.5 is smooth, with none of the rough edges we've seen from other frontier models. The speed improvements are remarkable.
Frequently asked questions
We offer Claude models across the spectrum of speed, price, and performance. Opus 4.5 is our most intelligent model to date. We recommend Opus 4.5 for your most demanding use cases where you need frontier intelligence—particularly production-ready code, sophisticated AI agents, and complex document creation.
Pricing depends on how you want to use Opus 4.5. To learn more, check out our pricing page.
Opus 4.5 is both a standard model and a hybrid reasoning model in one. You can pick when you want the model to answer normally and when you want it to use extended thinking.
Extended thinking mode is best for use cases where performance and accuracy matter more than latency. It significantly improves response quality for complex reasoning tasks, extended agentic work, multi-step coding projects, and deep research, and the thinking summaries help you understand key aspects of the model’s reasoning process.